

加快儀表板速度
如何讓您的儀表板載入速度更快。
當涉及到儀表板效能時,基本上有四種方法可以讓儀表板載入速度更快
- 要求較少資料.
- 快取問題的答案.
- 組織資料以預期常見問題.
- 提出有效率的問題。
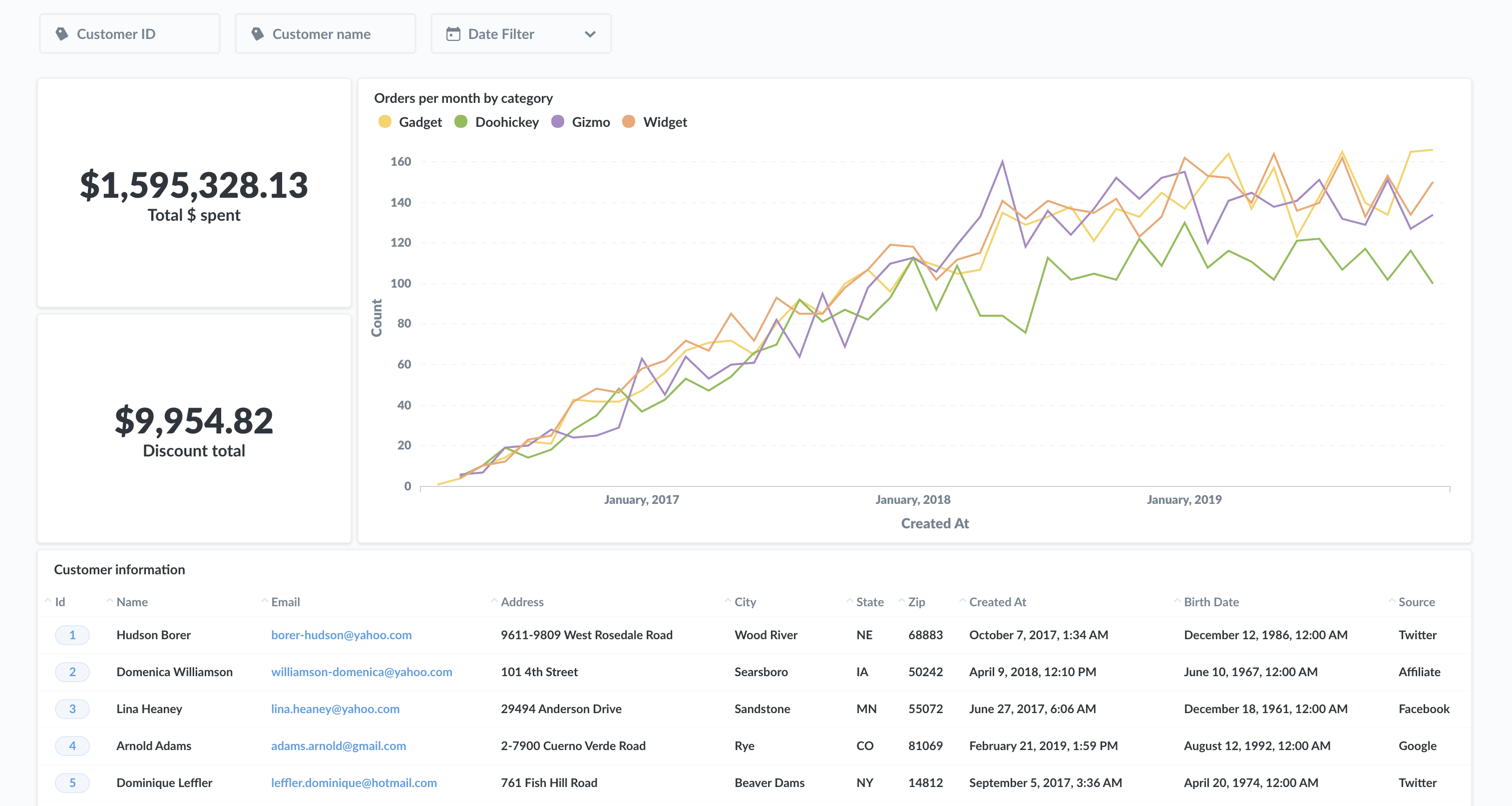
以下是一些關於如何讓您的儀表板載入速度更快的通用指南。此指南的大部分將著重於第三點,或您如何組織資料以預期將用於回答資料的最常見問題。
關於過早最佳化是萬惡之源的常見警告適用。我們的建議假設您已探索您的資料一段時間,並且從資料產生的洞察中獲得實質利益。只有在那時,您才應該問:「我該如何讓此儀表板載入速度更快?」
要求較少資料
這一點幾乎太過明顯,以至於經常被忽略,但它應該是第一個開始的地方。您是否真的需要您正在查詢的資料?即使您確實需要所有這些資料,您需要多久一次?
您可以透過限制您查詢的資料來節省大量時間,例如透過在儀表板上加入預設篩選器。請特別注意跨時間和空間的資料:您真的需要每天查看上季的資料嗎?或者您真的需要每個國家的每筆交易嗎?
即使您確實需要知道該資訊,您每天都需要嗎?您可以將該問題重新放置到另一個通常僅每週或每月檢閱一次的儀表板嗎?
當我們探索我們的資料集時,我們應該對所有資料持開放態度,但一旦我們確定我們的組織需要做出的決策類型,以及我們需要告知這些決策的資料,我們就應該無情地排除那些沒有顯著改善我們分析的資料。
快取問題的答案
如果資料已載入,您就不需要等待資料。管理員可以設定 Metabase 以快取查詢結果,這將儲存問題的答案。如果您有一組儀表板,每個人在早上第一次開啟電腦時都會執行這些儀表板,請提前執行該儀表板,並且該儀表板中的問題將使用已儲存的結果,以便在幾秒鐘內載入。人們將有權選擇重新整理資料,但通常這是不必要的,因為大多數情況下,人們只需要檢閱前一天及之前的資料。
管理員可以在管理面板的效能標籤中設定快取規則。您可以選擇將快取保留數小時、使用設定的排程來使快取失效,或使用查詢的平均執行時間來決定快取其結果的時間長度。
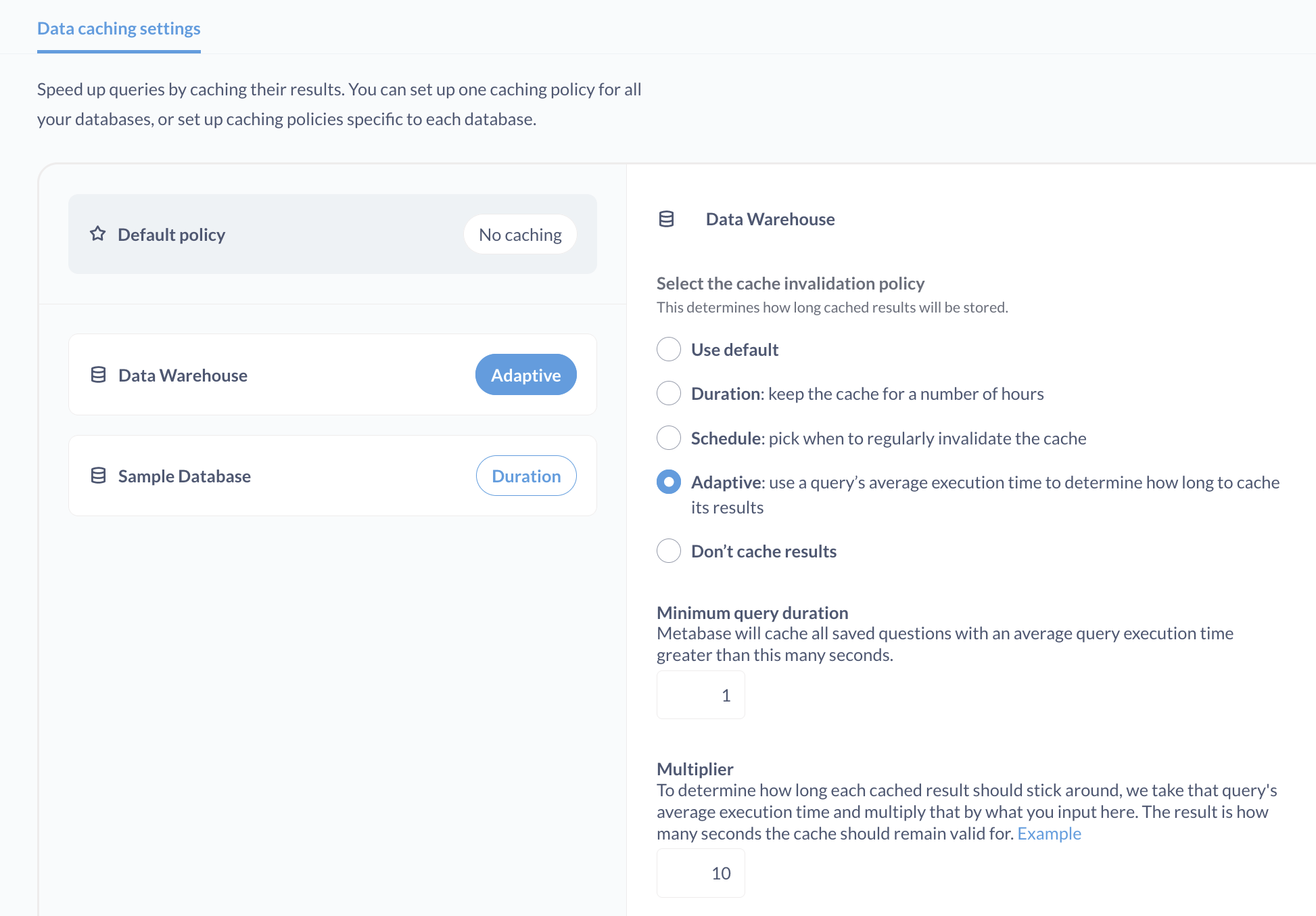
在專業版和企業版方案中,您也可以設定特定於個別儀表板和問題的快取原則。
您可以使用 Metabase 的使用量分析來判斷人們通常何時執行各種問題,然後使用Metabase 的 API建立指令碼,以程式設計方式提前執行這些問題(從而快取其結果)。這樣一來,當人們登入並瀏覽至其儀表板時,結果會在幾秒鐘內載入。即使沒有採取額外的「預熱」步驟,當您的第一個人載入該慢速查詢時,它也會為您的其餘人員快取。
組織資料以預期常見問題
您可以做的下一個最好的事情是以這樣一種方式組織您的資料,使其預期將被提出的問題,這將使您的資料庫更容易檢索該資料。
- 為經常查詢的欄編製索引.
- 複製您的資料庫.
- 反正規化資料.
- 具體化檢視:建立新表格以儲存查詢結果.
- 使用摘要表格提前彙總資料.
- 將資料從 JSON 中提取出來,並將其索引鍵插入欄中.
- 考慮使用特定於分析的資料庫.
以下除了最後一個章節外,都假設您正在使用傳統的關聯式資料庫,如 PostgreSQL 或 MySQL。最後一個章節是關於轉移到完全不同類型的資料庫,該資料庫專門針對處理分析進行了調整,並且應該是您的最後手段,尤其是對於新創公司而言。
為經常查詢的欄編製索引
為您的資料庫新增索引可以顯著提高查詢效能。但正如為書中所有內容編製索引沒有意義一樣,索引確實會產生一些額外負擔,因此應策略性地使用它們。
如何策略性地使用索引?找出您查詢次數最多的表格,以及這些表格中最常查詢的欄。您可以諮詢您的個別資料庫以取得此中繼資料。例如,PostgreSQL 透過其 pg_stat_statements 模組提供關於查詢數量和效能的中繼資料。
請記住,也要做簡單的工作,詢問您的 Metabase 使用者哪些問題和儀表板對他們很重要,以及他們是否也遇到任何「速度緩慢」的情況。最常需要編製索引的欄位是基於時間或基於 ID 的欄位—考慮事件資料上的時間戳記,或類別資料上的 ID。
或者,在專業版和企業版方案中,您可以使用 Metabase 的使用量分析,這可以輕鬆查看誰在執行哪些查詢、頻率以及這些查詢花費多長時間才能傳回記錄。
一旦您確定要編製索引的表格和欄,請查閱您的資料庫文件以了解如何設定索引(例如,這是 PostgreSQL 中的索引)。
索引很容易設定(和移除)。以下是 CREATE INDEX 陳述式的基本格式
CREATE INDEX index_name ON table_name (column_name)
例如
CREATE INDEX orders_id_index ON orders (id)
試驗索引以查看如何提高查詢效能。如果您的使用者經常在單一表格上使用多個篩選器,請研究使用複合索引。
複製您的資料庫
如果您正在使用資料庫來處理操作(例如,應用程式交易,如下訂單、更新個人資料資訊等)以及分析(例如,用於支援 Metabase 儀表板的查詢),請考慮建立該生產資料庫的複本,以用作僅限分析的資料庫。將 Metabase 連線到該複本,每晚更新複本,並讓您的分析師進行查詢。分析師的長時間執行查詢不會干擾您的生產資料庫的日常操作,反之亦然。
除了加快儀表板速度外,保留用於資料分析的複本資料庫也是一個很好的做法,可以避免可能長時間執行的分析查詢影響您的生產環境。
反正規化資料
在某些情況下,反正規化您的某些表格(即,將多個表格合併為具有更多欄的較大表格)可能是有意義的。您最終將儲存一些多餘的資料(例如,每次使用者下訂單時都包含使用者資訊),但分析師不必聯結多個表格即可取得他們需要回答問題的資料。
具體化檢視:建立新表格以儲存查詢結果
透過具體化檢視,您將在表格中保留原始、反正規化的資料,並建立新表格(通常在非工作時間)以儲存查詢結果,這些結果以預期分析師將提出的問題的方式合併來自多個表格的資料。
例如,您可能會將訂單和產品資訊儲存在不同的表格中。您可以每天晚上建立(或更新)具體化檢視,將這兩個表格中最常查詢的欄合併,並將該具體化檢視連線到您在 Metabase 中的問題。如果您同時使用資料庫進行生產和分析,除了消除合併該資料所需的聯結過程外,您的查詢也不必與這些表格上的生產讀取和寫入競爭。
具體化檢視與通用表格運算式(CTE,有時稱為檢視)之間的區別在於,具體化檢視將其結果儲存在資料庫中(因此可以編製索引)。CTE 本質上是子查詢,並且每次都會計算。它們可能會被快取,但不會儲存在資料庫中。
但是,具體化檢視將消耗您資料庫中的資源,並且您必須手動更新檢視 (refresh materialized view [name])。
使用摘要表格提前彙總資料
這裡的想法是使用具體化檢視—甚至是一組單獨的表格—來建立摘要表格,以最大限度地減少計算。假設您有數百萬列的表格,並且您想要彙總多個欄中的資料。您可以根據一個或多個表格的彙總建立具體化檢視,這將執行初始(耗時)計算。您可以建立查詢該摘要表格以取得前一天晚上計算的資料,而不是讓儀表板查詢和計算該原始資料一天數次。
例如,您可以有一個包含所有訂單表格的訂單表格,以及一個每晚更新並儲存彙總和其他彙總資料(如每週、每月等的訂單總額)的訂單摘要表格。如果有人想要檢視用於計算該彙總的個別訂單,您可以使用自訂目的地將使用者連結到確實查詢原始資料的問題或儀表板。
將資料從 JSON 中提取出來,並將其索引鍵插入欄中
我們經常看到組織將 JSON 物件儲存在關聯式資料庫(如 MySQL 或 PostgreSQL)的單一欄中。通常,這些組織正在儲存來自事件分析軟體(如 Segment 或 Amplitude)的 JSON 酬載。
儘管某些資料庫可以為 JSON 編製索引(例如,PostgreSQL 可以為 JSON 二進位檔編製索引),但您仍然必須每次都抓取完整的 JSON 物件,即使您只對物件中的單一索引鍵值對感興趣。相反,請考慮從這些 JSON 物件中提取每個欄位,並將這些索引鍵對應到表格中的欄。
考慮使用針對分析最佳化的資料庫
如果您已完成以上所有操作,並且儀表板載入時間的長度仍然干擾您及時做出決策的能力,您應該考慮使用專門針對欄位分析查詢而建構的資料庫。這些資料庫稱為線上分析處理 (OLAP) 資料庫(有時稱為資料倉儲)。
傳統的關聯式資料庫(如 PostgreSQL 和 MySQL)是為交易處理而設計的,並且被歸類為線上交易處理 (OLTP) 資料庫。這些資料庫更適合用作操作資料庫,例如儲存網站或行動應用程式的資料。它們非常擅長處理以下情境:有人向您的網站提交了經過深思熟慮、切題且絕非煽動性的評論,您的應用程式會向您的後端發出 POST 請求,後端會將評論和中繼資料路由到您的資料庫以進行儲存。OLTP 資料庫可以處理大量並行交易,如評論貼文、購物車結帳、個人資料簡介更新等。
OLAP 和 OLTP 系統之間的主要區別在於,OLAP 資料庫最佳化了分析查詢,如總和、彙總以及對大量資料的其他分析操作,以及大量匯入(透過ETL),而 OLTP 資料庫必須平衡來自資料庫的大量讀取與其他交易類型:小型插入、更新和刪除。
OLAP 通常使用欄式儲存。傳統 (OLTP) 關聯式資料庫按列儲存資料,而使用欄式儲存的資料庫(毫不奇怪)按欄儲存資料。這種欄式儲存策略使 OLAP 資料庫在讀取資料時具有優勢,因為查詢不必篩選不相關的列。這些資料庫中的資料通常以事實和維度表格組織,其中(通常是大量的)事實表格容納事件。每個事件都包含屬性清單和對維度表格的外鍵參考,維度表格包含關於這些事件的資訊:誰參與其中、發生了什麼、產品資訊等等。
Metabase 支援多個熱門資料倉儲:Google BigQuery、Amazon Redshift、Snowflake 和 Apache Druid(專門用於即時分析)。Metabase 也支援 Presto,這是一個查詢引擎,可以與各種不同的資料儲存區配對,包括 Amazon S3。
當您開始使用 Metabase 時,請不要過於擔心底層資料儲存區。但是隨著您的資料成長,以及Metabase 的採用率提高,請留意您可能想要調查使用資料倉儲的指標。例如,Redshift 可以查詢 PB 級資料,並擴展到查詢 Amazon S3 中的歷史資料。Snowflake 允許您隨著組織的成長動態擴展您的運算資源。
延伸閱讀
如需更多關於改善效能的秘訣,請查看我們關於擴展 Metabase 和 SQL 查詢最佳實務的文章。
如果您改善了您組織的儀表板效能,您可以在我們的論壇上分享您的秘訣。
下一步:大規模 Metabase
擴展 Metabase 以支援更多人員和資料庫的最佳實務。