

撰寫 SQL 查詢的最佳實務
SQL 最佳實務:撰寫更優良 SQL 查詢的簡短指南。
本文涵蓋資料分析師和資料科學家撰寫 SQL 查詢的一些最佳實務。我們大部分的討論將著重於一般 SQL,但我們也會加入一些關於 Metabase 特定功能的注意事項,這些功能讓撰寫 SQL 變得輕而易舉。
正確性、可讀性,然後才是最佳化:依序進行
這裡適用關於過早最佳化的標準警告。在您確定查詢會傳回您要尋找的資料之前,請避免調整 SQL 查詢。即使在那之後,也只有在查詢頻繁執行 (例如為熱門儀表板提供資料),或查詢橫跨大量資料列時,才優先考量最佳化查詢。一般而言,請在擔心效能之前,優先考量準確性 (查詢是否產生預期的結果) 和可讀性 (其他人是否可以輕鬆理解和修改程式碼)。
先盡可能縮小乾草堆,再搜尋針
可以說,我們已經開始討論最佳化,但目標應該是告訴資料庫掃描最少量的必要值以擷取您的結果。
SQL 的美妙之處在於其宣告式本質。您只需要告訴資料庫您需要哪些記錄,資料庫就會找出最有效率的方式來取得該資訊,而無需告訴資料庫如何擷取記錄。因此,關於提高查詢效率的大部分建議,只是在於向人們展示如何使用 SQL 中的工具,更精確地表達他們的需求。
我們將檢閱查詢執行的一般順序,並沿途提供提示以縮小您的搜尋空間。然後,我們將討論要新增到您的工具帶中的三個基本工具:INDEX、EXPLAIN 和 WITH。
首先,瞭解您的資料
在您撰寫任何程式碼行之前,先熟悉您的資料,方法是研究中繼資料,以確保欄位的確包含您預期的資料。Metabase 中的 SQL 編輯器具有方便的資料參考索引標籤 (可透過書籍圖示存取),您可以在其中瀏覽資料庫中的表格,並檢視其欄位和連線
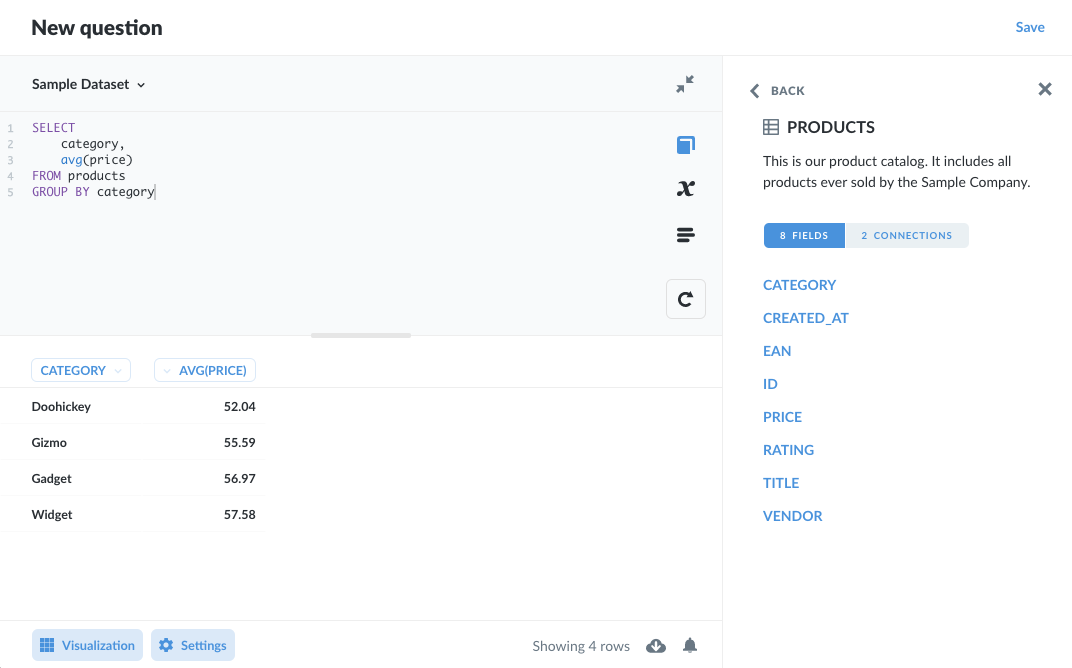
您也可以檢視特定欄位的範例值
Metabase 提供您許多不同的方式來探索您的資料:您可以 X 光檢視表格、使用查詢產生器撰寫問題、將已儲存的問題轉換為 SQL 程式碼,或從現有的 SQL 查詢建立。我們在其他文章中涵蓋了這一點;現在,讓我們來看看查詢的一般工作流程。
開發您的查詢
每個人的方法都會有所不同,但以下是在開發查詢時可遵循的工作流程範例。
- 如上所述,研究欄位和表格中繼資料。如果您使用的是 Metabase 的原生 (SQL) 編輯器,您也可以搜尋包含您正在使用的表格和欄位之 SQL 程式碼的 SQL 片段。片段可讓您瞭解其他分析師如何查詢資料。或者您可以從現有的 SQL 問題開始查詢。
- 為了感受表格的值,請從您正在使用的表格中 SELECT * 並 LIMIT 您的結果。在您精簡欄位 (或透過聯結新增更多欄位) 時,請保持 LIMIT 應用。
- 將欄位縮減為回答您的問題所需的最少集合。
- 將任何篩選器套用至這些欄位。
- 如果您需要彙總資料,請彙總少量資料列,並確認彙總符合您的預期。
- 一旦您有查詢傳回您需要的結果,請尋找查詢的區段以儲存為通用表格運算式 (CTE) 以封裝該邏輯。
- 使用 Metabase,您也可以將程式碼儲存為 SQL 片段,以便在其他查詢中分享和重複使用。
查詢執行的一般順序
在我們深入探討撰寫 SQL 程式碼的個別提示之前,務必先瞭解資料庫將如何執行您的查詢。這與您用來撰寫查詢的閱讀順序 (從左到右、從上到下) 不同。查詢最佳化工具可以變更以下清單的順序,但撰寫 SQL 時最好記住 SQL 查詢的此一般生命週期。我們將使用執行順序來分組以下撰寫優良 SQL 的提示。
此處的經驗法則是:您在此清單中越早消除資料,就越好。
- FROM (和 JOIN) 取得查詢中參考的表格。這些表格代表您的查詢指定的最大搜尋空間。在可能的情況下,請在繼續之前限制此搜尋空間。
- WHERE 篩選資料。
- GROUP BY 彙總資料。
- HAVING 篩選掉不符合條件的彙總資料。
- SELECT 抓取欄位 (然後在叫用 DISTINCT 時移除重複的資料列)。
- UNION 將選取的資料合併到結果集中。
- ORDER BY 排序結果。
而且,當然,在某些情況下,您的特定資料庫的查詢最佳化工具會設計不同的查詢計畫,因此請勿過於拘泥於此順序。
一些查詢指南 (而非規則)
以下提示為指南,而非規則,旨在讓您避免遇到麻煩。每個資料庫處理 SQL 的方式都不同,具有稍微不同的功能集,並採用不同的方法來最佳化查詢。而這還不包括我們將傳統交易資料庫與使用欄式儲存格式的分析資料庫進行比較,後者具有截然不同的效能特性。
為您的程式碼加上註解,尤其是原因
藉由新增註解來說明程式碼的不同部分,來幫助其他人 (包括三個月後的您自己)。此處要捕捉的最重要內容是「原因」。例如,很明顯地,以下程式碼會篩選掉 ID 大於 10 的訂單,但這樣做的原因是前 10 個訂單用於測試。
SELECT
id,
product
FROM
orders
-- filter out test orders
WHERE
order.id > 10
此處的問題是您引入了一些維護負擔:如果您變更程式碼,則需要確保註解仍然相關且為最新狀態。但為了程式碼的可讀性,這是很小的代價。
FROM 的 SQL 最佳實務
使用 ON 關鍵字聯結表格
雖然可以使用 WHERE 子句「聯結」兩個表格 (也就是執行隱含聯結,例如 SELECT * FROM a,b WHERE a.foo = b.bar),但您應該改為偏好明確的 JOIN
SELECT
o.id,
o.total,
p.vendor
FROM
orders AS o
JOIN products AS p ON o.product_id = p.id
主要為了提高可讀性,因為 JOIN + ON 語法可區分聯結與旨在篩選結果的 WHERE 子句。
別名多個表格
在查詢多個表格時,請使用別名,並在您的 select 陳述式中使用這些別名,讓資料庫 (和您的讀者) 不需要剖析哪個欄位屬於哪個表格。請注意,如果您的多個表格中都有名稱相同的欄位,則需要使用表格名稱或別名明確參考它們。
避免
SELECT
title,
last_name,
first_name
FROM fiction_books
LEFT JOIN fiction_authors
ON fiction_books.author_id = fiction_authors.id
偏好
SELECT
books.title,
authors.last_name,
authors.first_name
FROM fiction_books AS books
LEFT JOIN fiction_authors AS authors
ON books.author_id = authors.id
這是一個簡單的範例,但是當查詢中的表格和欄位數量增加時,您的讀者就不必追蹤哪個欄位在哪個表格中。而且,如果您聯結具有不明確欄位名稱的表格 (例如,兩個表格都包含名為 Created_At 的欄位),您的查詢可能會中斷。
請注意,欄位篩選器與表格別名不相容,因此在將篩選器小工具連線到您的欄位篩選器時,您需要移除別名。
WHERE 的 SQL 最佳實務
在 HAVING 之前使用 WHERE 進行篩選
使用 WHERE 子句篩選掉多餘的資料列,這樣您就不必首先計算這些值。只有在移除不相關的資料列,並在彙總這些資料列並將其分組之後,您才應該加入 HAVING 子句以篩選掉彙總。
避免在 WHERE 子句中的欄位上使用函式
在 WHERE 子句中的欄位上使用函式可能會大幅減慢您的查詢速度,因為該函式會使查詢變成不可搜尋 (亦即,它會阻止資料庫使用索引來加速查詢)。欄位上的函式不會使用索引跳到相關資料列,而是強制資料庫在表格的每個資料列上執行該函式。
請記住,串連運算子 || 也是一個函式,因此請勿嘗試使用串連字串來篩選多個欄位。改為偏好多個條件
避免
SELECT hero, sidekick
FROM superheros
WHERE hero || sidekick = 'BatmanRobin'
偏好
SELECT hero, sidekick
FROM superheros
WHERE
hero = 'Batman'
AND
sidekick = 'Robin'
偏好 = 而非 LIKE
這並非總是如此。最好瞭解 LIKE 會比較字元,並且可以與萬用字元運算子 (例如 %) 配對,而 = 運算子會比較字串和數字以進行完全比對。= 可以利用索引欄位的優勢。並非所有資料庫都是如此,因為只要您避免在搜尋詞彙前加上萬用字元運算子 %,LIKE 就可以使用索引 (如果欄位存在索引)。
這將我們帶到下一個重點
避免在 WHERE 陳述式中前後加上萬用字元
避免
SELECT column FROM table WHERE col LIKE "%wizar%"
偏好
SELECT column FROM table WHERE col LIKE "wizar%"
使用萬用字元進行搜尋可能很耗費資源。偏好將萬用字元新增到字串結尾。在字串前加上萬用字元可能會導致完整表格掃描。
偏好 EXISTS 而非 IN
如果您只需要驗證表格中是否存在值,請偏好 EXISTS 而非 IN,因為 EXISTS 程序會在找到搜尋值後立即結束,而 IN 會掃描整個表格。IN 應該用於尋找清單中的值。
同樣地,偏好 NOT EXISTS 而非 NOT IN。
GROUP BY 的 SQL 最佳實務
依遞減基數排序多個群組
在可能的情況下,依遞減基數順序 GROUP BY 欄位。也就是說,先依具有較多唯一值的欄位 (例如 ID 或電話號碼) 分組,再依具有較少相異值的欄位 (例如州或性別) 分組。
HAVING 的 SQL 最佳實務
僅使用 HAVING 篩選彙總
在 HAVING 之前,先使用 WHERE 子句篩選掉值,然後再彙總和分組這些值。
SELECT 的 SQL 最佳實務
SELECT 欄位,而非星號
指定您想要包含在結果中的欄位 (雖然在第一次探索表格時可以使用 *,但請記得 LIMIT 您的結果)。
UNION 的 SQL 最佳實務
偏好 UNION All 而非 UNION
如果重複項目不是問題,UNION ALL 就不會捨棄它們,而且由於 UNION ALL 的任務不是移除重複項目,因此查詢會更有效率。
ORDER BY 的 SQL 最佳實務
盡可能避免排序,尤其是在子查詢中
排序很耗費資源。如果您必須排序,請確保您的子查詢不會不必要地排序資料。
INDEX 的 SQL 最佳實務
本節適用於在場的資料庫管理員 (以及一個太過龐大而無法放入本文的主題)。人們在資料庫查詢中遇到效能問題時,最常見的事情之一是缺乏足夠的索引。
您應該為哪些欄位建立索引通常取決於您要篩選的欄位 (亦即,通常在您的 WHERE 子句中結尾的欄位)。如果您發現您總是依一組常見的欄位進行篩選,則應考慮為這些欄位建立索引。
新增索引
CREATE INDEX product_title_index ON products (title)
目前有不同類型的索引可供使用,最常見的索引類型是使用 B 樹 來加速檢索。請查看我們關於 加快儀表板速度 的文章,並查閱您的資料庫文件,以了解如何建立索引。
使用部分索引
對於特別龐大的資料集或是不平衡的資料集(某些值範圍出現頻率較高),請考慮建立帶有 WHERE 子句的索引,以限制索引的列數。部分索引對於日期範圍也很有用,例如,如果您只想為過去一週的資料建立索引。
使用複合索引
對於通常在查詢中一起使用的欄位(例如 last_name、first_name),請考慮建立複合索引。語法與建立單一索引類似。例如:
CREATE INDEX full_name_index ON customers (last_name, first_name)
EXPLAIN
尋找瓶頸
某些資料庫(如 PostgreSQL)可以根據您的 SQL 程式碼提供查詢計畫的深入資訊。只需在您的程式碼前加上關鍵字 EXPLAIN ANALYZE。您可以使用這些命令來檢查您的查詢計畫並尋找瓶頸,或者比較查詢的不同版本之間的計畫,以查看哪個版本更有效率。
以下是使用 PostgreSQL 提供的 dvdrental 範例資料庫的範例查詢。
EXPLAIN ANALYZE SELECT title, release_year
FROM film
WHERE release_year > 2000;
以及輸出結果
Seq Scan on film (cost=0.00..66.50 rows=1000 width=19) (actual time=0.008..0.311 rows=1000 loops=1)
Filter: ((release_year)::integer > 2000)
Planning Time: 0.062 ms
Execution Time: 0.416 ms
您會看到規劃時間、執行時間以及成本、列數、寬度、次數、迴圈、記憶體使用量等所需的毫秒數。閱讀這些分析報告在某種程度上是一門藝術,但您可以使用它們來識別查詢中的問題區域(例如巢狀迴圈或可能受益於索引的欄位),以便您進行優化。
這裡是 PostreSQL 關於 使用 EXPLAIN 的文件。
WITH
使用通用表格運算式 (CTE) 來組織您的查詢
使用 WITH 子句將邏輯封裝在通用表格運算式 (CTE) 中。以下範例查詢尋找 2019 年每單位銷售平均收入最高的產品,以及最大值和最小值。
WITH product_orders AS (
SELECT o.created_at AS order_date,
p.title AS product_title,
(o.subtotal / o.quantity) AS revenue_per_unit
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
-- Filter out orders placed by customer service for charging customers
WHERE o.quantity > 0
)
SELECT product_title AS product,
AVG(revenue_per_unit) AS avg_revenue_per_unit,
MAX(revenue_per_unit) AS max_revenue_per_unit,
MIN(revenue_per_unit) AS min_revenue_per_unit
FROM product_orders
WHERE order_date BETWEEN '2019-01-01' AND '2019-12-31'
GROUP BY product
ORDER BY avg_revenue_per_unit DESC
WITH 子句使程式碼更易於閱讀,因為主查詢(您實際要尋找的內容)不會被冗長的子查詢打斷。
您也可以使用 CTE 來使您的 SQL 更易於閱讀,例如,如果您的資料庫具有名稱笨拙的欄位,或者需要一些資料處理才能取得有用的資料。例如,當處理 JSON 欄位時,CTE 可能很有用。以下範例說明如何從使用者事件的 JSON blob 中提取和轉換欄位。
WITH source_data AS (
SELECT events->'data'->>'name' AS event_name,
CAST(events->'data'->>'ts' AS timestamp) AS event_timestamp
CAST(events->'data'->>'cust_id' AS int) AS customer_id
FROM user_activity
)
SELECT event_name,
event_timestamp,
customer_id
FROM source_data
或者,您可以將子查詢另存為 SQL 片段
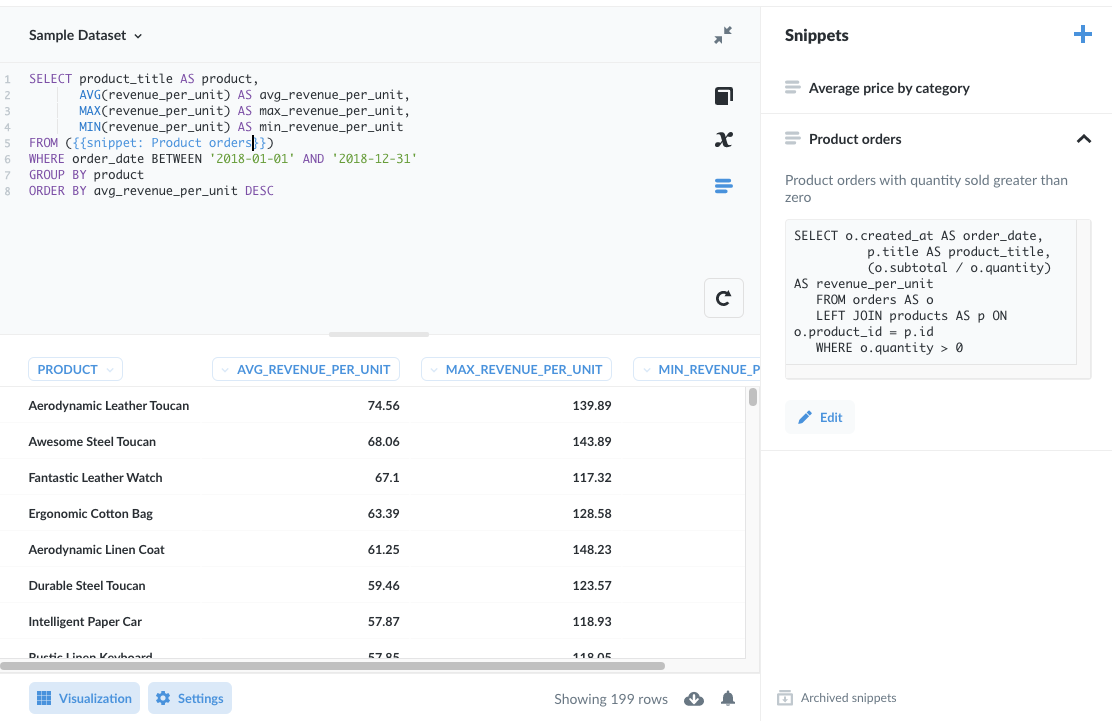
是的,正如您可能預期的那樣,「空氣動力皮革巨嘴鳥」的每單位銷售平均收入最高。
使用 Metabase,您甚至不必使用 SQL
SQL 很棒。但 Metabase 的 查詢產生器 也很棒。您可以使用 Metabase 的圖形介面來編寫查詢,以聯結表格、篩選和匯總資料、建立自訂欄位等等。透過自訂運算式,您可以處理絕大多數的分析用例,而無需使用 SQL。使用查詢產生器編寫的問題也受益於自動向下鑽取功能,這允許您的圖表查看者點擊並瀏覽資料,這是以 SQL 編寫的問題所不具備的功能。
是否有明顯的錯誤或遺漏?
關於 SQL 的書籍汗牛充棟,因此我們在這裡僅觸及皮毛。您可以在我們的論壇上與其他 Metabase 使用者分享您的 SQL 魔法秘訣。
下一步:在 SQL 中使用日期
使用 SQL 按時間段對結果進行分組、比較每週總數,並找出兩個日期之間的持續時間。