

在 SQL 中使用日期
使用 SQL 按時間週期分組結果、比較每週總計,並找出兩個日期之間的天數。
我們將逐步說明在 SQL 中使用日期的三種常見情境。我們將使用 Metabase 隨附的範例資料庫,以便您可以跟著操作,並堅持使用適用於許多資料庫的一些常見 SQL 函數和技術。我們假設這不是您的第一個 SQL 查詢,並且您希望提升技能。但即使您剛開始入門,也應該能夠學到一些技巧。
| 情境 | 範例 |
|---|---|
| 按時間週期分組結果 | 每週有多少人建立帳戶? |
| 比較每週總計 | 本週的訂單數量與上週相比如何? |
| 找出兩個日期之間的天數 | 客戶建立帳戶和下第一筆訂單之間相隔多少天? |
按時間週期分組結果
我們經常想要提出以下問題:每個月有多少客戶註冊?或每週下了多少訂單?在這裡,我們將瀏覽結果表格,計算列數,並按時間週期對這些計數進行分組。
範例:每週有多少人建立帳戶?
在這裡,我們希望傳回兩欄
| WEEK | ACCOUNTS CREATED |
|------|------------------|
| ... | ... |
讓我們看一下我們的「人員」表格。我們可以執行 SELECT * FROM people LIMIT 1 來查看欄位清單,或直接點擊書本圖示來查看我們正在使用的資料庫中表格的中繼資料。
由於我們對客戶何時註冊帳戶感興趣,因此我們需要 created_at 欄位,根據我們的資料參考,該欄位是「使用者記錄建立的日期」。也稱為使用者的「加入日期」。」
我們需要將這些帳戶建立分組,但不是按日期分組,而是需要按週分組。為了查看每個 created_at 日期屬於哪一週,我們將使用 DATE_TRUNC 函數。
DATE_TRUNC 可讓您將時間戳記四捨五入(「截斷」)到您關心的粒度:週、月等等。DATE_TRUNC 接受兩個引數:文字和時間戳記,並傳回時間戳記。第一個文字引數是時間週期,在本例中為「週」,但我們可以指定不同的粒度,例如月、季或年(請查看資料庫中關於 DATE_TRUNC 的文件以查看選項)。為了我們的目的,我們將撰寫 DATE_TRUNC('week', created_at),它將傳回每週一的日期。順便說一句,SQL 不區分大小寫,因此您可以隨意設定程式碼的大小寫(date_trunc 也有效,如果您是諷刺性地查詢,則 DaTe_TrUnc 也有效)。
我們也將為結果使用別名,以便為欄位提供更具體的名稱。例如,使用 AS 關鍵字,我們將把 Count(*) 變更為顯示為 accounts_created。
SELECT
DATE_TRUNC('week', created_at) AS week,
COUNT(*) AS accounts_created
FROM
people
GROUP BY
week
ORDER BY
week
傳回
| WEEK | ACCOUNTS_CREATED |
|---------|------------------|
| 4/18/16 | 13 |
| 4/25/16 | 17 |
| 5/2/16 | 17 |
| ... | ... |
我們可以將此結果視覺化為折線圖
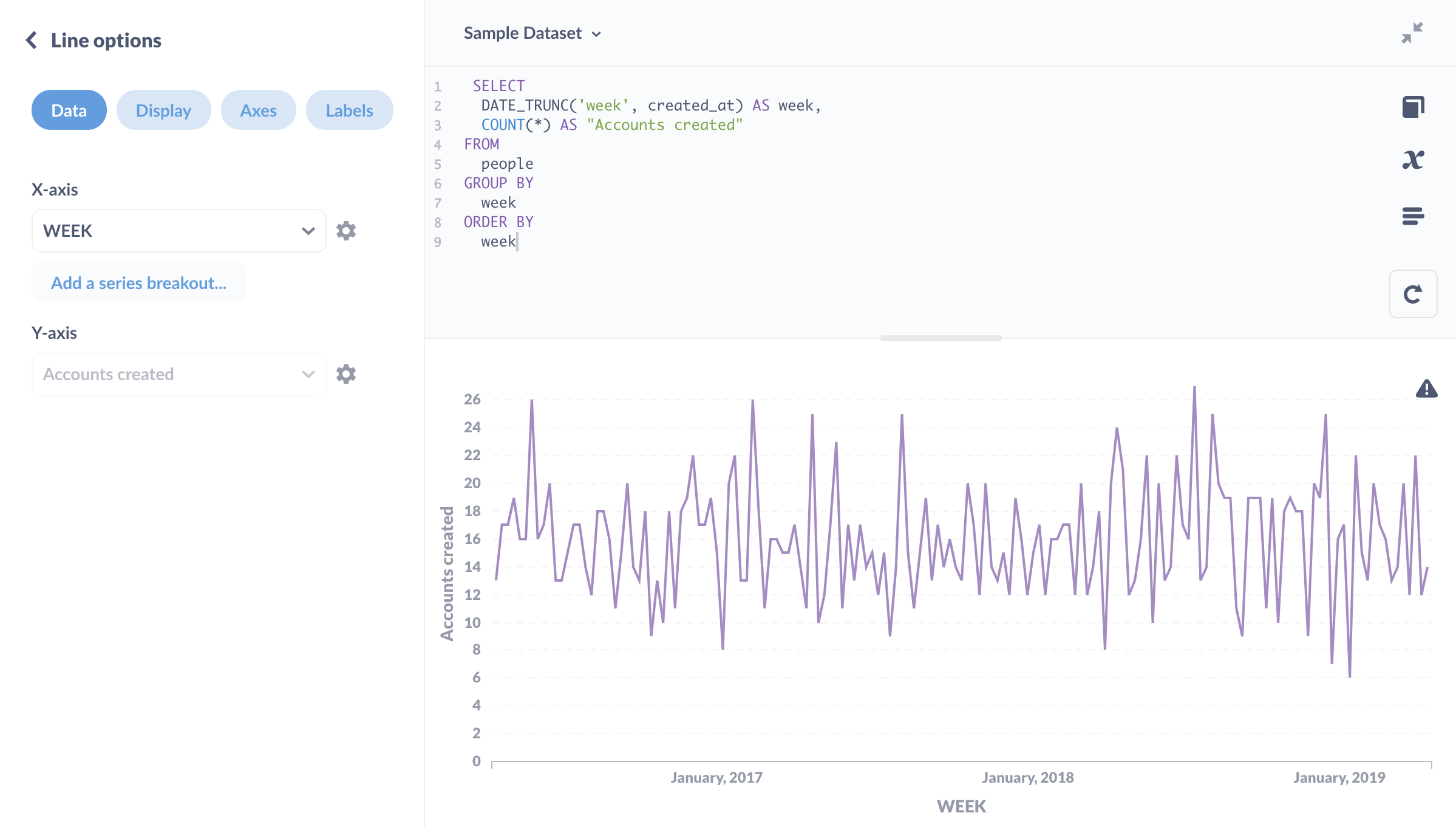
看起來與我們從隨機資料集預期的結果非常相似。
比較每週總計
您通常會想查看計數從一週到下一週的變化情況,您可以透過將表格聯結到自身,並將每週與前一週進行比較來計算。
範例:訂單與上週相比如何?
我們在這裡尋找的是週、該週的訂單計數以及每週變化(訂單是增加、減少還是保持不變?)
| WEEK | COUNT_OF_ORDERS | WOW_CHANGE |
|---------|-----------------|------------|
| ... | ... | ... |
為了取得此資料,我們首先需要取得一個表格,列出每週的訂單計數。我們將執行與我們剛才對「人員」表格執行的基本相同的操作,但這次是對「訂單」表格執行:我們將使用 DATE_TRUNC 按週分組訂單計數。
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
得到
| WEEK | ORDER_COUNT |
|----------|-------------|
| 7/1/2019 | 115 |
| 7/2/2018 | 119 |
| 7/3/2017 | 78 |
| ... | ... |
我們將使用這些結果來建立查詢的其餘部分。我們現在需要做的是從每週的訂單計數(我們將其稱為 w1)中,減去前一週的計數(我們將其稱為 w2)。這裡的挑戰是,為了執行減法,我們需要以某種方式將每週的計數與前一週的計數放在同一列中。
以下是我們的做法
- 將我們的結果包裝在通用表格運算式 (CTE) 中。
- 透過將聯結偏移 1 週,將該 CTE 聯結到自身
- 從每週的總計中減去前一週的訂單計數總計,以取得每週變化
我們將使用 WITH 關鍵字將上述查詢建立為通用表格運算式 (CTE)。本質上,CTE 是一種將變數指派給臨時結果的方法,然後我們可以將這些結果視為資料庫中的實際表格(例如「訂單」或「表格」)。我們將結果表格命名為 order_count_by_week。然後我們將使用此表格並將其聯結到自身,但帶有偏移:其列偏移了一週。
以下是帶有偏移聯結的查詢
WITH order_count_by_week AS (
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
)
SELECT
*
FROM
order_count_by_week w1
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
ORDER BY
w1.week
此查詢產生
| WEEK | ORDER_COUNT | WEEK | ORDER_COUNT |
|-----------|-------------|-----------|-------------|
| 4/25/2016 | 1 | | |
| 5/2/2016 | 3 | 4/25/2016 | 1 |
| 5/9/2016 | 3 | 5/2/2016 | 3 |
| ... | ... | ... | ... |
讓我們解開這裡發生的事情。我們將 order_count_by_week CTE 別名為 w1,然後再次別名為 w2。接下來,我們將這兩個 CTE 左聯結。這裡的關鍵是 DATEADD 函數,我們使用它為每個 w2.week 值新增一週,以偏移聯結的欄位
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
DATEADD 函數接受時間週期 (WEEK)、要套用的週數(在本例中為 1,因為我們想知道與一週前的差異)以及要套用加法的日期欄位 (w2.week)。(請注意,某些資料庫使用 INTERVAL 而不是 DATEADD,例如 w2.week + INTERVAL '1 week')。這會「對齊」列,但偏移一週(請注意上面第一列的第二組週/訂單計數中缺少值)。
我們現在有一個表格,其中包含計算每列每週變化所需的一切。現在我們只需要修改我們的 select 陳述式,以傳回我們正在尋找的欄位
- 下訂單的週
- 該週的訂單計數
- 每週變化(即,本週計數與前一週計數之間的差異)。
以下是完整查詢
WITH order_count_by_week AS (
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
)
SELECT
w1.week,
w1.order_count AS count_of_orders,
w1.order_count - w2.order_count AS wow_change
FROM
order_count_by_week w1
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
ORDER BY
w1.week
傳回
| WEEK | COUNT_OF_ORDERS | WOW_CHANGE |
|---------|-----------------|------------|
| 4/25/16 | 1 | |
| 5/2/16 | 3 | 2 |
| 5/9/16 | 3 | 0 |
| ... | ... | ... |
找出兩個日期之間的天數
您通常會想找出兩個事件之間的時間長度:註冊和結帳之間經過的秒數,或結帳和交貨之間經過的天數。
範例:客戶建立帳戶和下第一筆訂單之間相隔多少天?
為了回答這個問題,讓我們傳回四欄
- 客戶 ID
- 客戶建立帳戶的日期
- 客戶下第一筆訂單的日期
- 這兩個日期之間的差異
現在,為了取得此資訊,我們需要從「人員」和「訂單」表格中抓取資料。但我們不想聯結這兩個表格,因為我們只需要每位客戶下的第一筆訂單。
讓我們從找出每位客戶何時下第一筆訂單開始。
SELECT
user_id,
MIN(created_at) as first_order_date
FROM
orders
GROUP BY
user_id
在這裡,我們按客戶分組訂單 (GROUP BY user_id) 並使用 MIN 函數來尋找最早的訂單日期。我們將這些結果儲存為 first_orders,然後繼續我們的查詢。
WITH first_orders AS (
SELECT
user_id,
MIN(created_at) as first_order_date
FROM
orders
GROUP BY
user_id
)
SELECT
people.id,
people.created_at AS account_creation,
first_orders.first_order_date,
DATEDIFF(
'day', people.created_at, first_orders.first_order_date
) AS days_before_first_order
FROM
PEOPLE
JOIN first_orders ON first_orders.user_id = people.id
ORDER BY
account_creation
得到
| ID | ACCOUNT_CREATION | FIRST_ORDER_DATE | DAYS_BEFORE_FIRST_ORDER |
|------|------------------|------------------|-------------------------|
| 915 | 4/19/16 21:35 | 10/9/16 8:42 | 173 |
| 1712 | 4/21/16 23:46 | 8/15/16 4:01 | 116 |
| 2379 | 4/22/16 4:07 | 5/22/16 3:56 | 30 |
| ... | ... | ... | ... |
總而言之:我們抓取了客戶的 created_at 日期,並將查詢聯結到我們的 CTE。我們使用 DATEDIFF 函數來尋找帳戶建立和第一筆訂單之間的天數,然後將結果儲存為 days_before_first_order。DATEDIFF 接受時間週期(例如「天」、「週」、「月」),並傳回兩個時間戳記之間的週期數。
(鑑於範例資料庫是隨機的,我們的回應與現實不太相符,人們在帳戶設定和購買之間等待 173 天的情況有多常見?)
延伸閱讀
我們希望這些查詢逐步解說為您自己的問題提供了一些想法,但請記住,不同的資料庫支援不同的 SQL 函數,因此養成在處理查詢時查閱資料庫文件的習慣。您也可以查看撰寫 SQL 查詢的最佳實務。如果您對聯結的工作原理有點模糊,請查看 Metabase 中的聯結。
下一步:使用通用表格運算式 (CTE) 簡化複雜查詢
CTE 是命名的結果集,有助於保持程式碼井然有序。它們可讓您在同一個查詢中重複使用結果,並執行多層次彙總。