


在數據驅動的世界中,企業需要準確且乾淨的數據才能做出明智的決策。乾淨的數據對於可靠的洞察、高效的營運以及最終的成功至關重要。
對於許多人來說,髒亂的數據仍然是一項重大挑戰,因為它可能導致不準確的分析和錯誤的決策。在本文中,我們將探討三種資料清理方法,讓您可以充分利用您的數據。
在 Metabase 中使用模型
在 Metabase 中實施資料清理程序,最好的方法之一是開發一個模型,根據特定條件表示數據。模型是 Metabase 中的基本建構區塊。它們可以比作衍生表格或特殊的儲存問題,作為新分析的起點。模型可以建立在 SQL 或查詢建立器問題之上,允許包含自訂和計算欄位。
Metabase 中模型的優點
- 使用者友善: 需要最少的技術專業知識。直接在分析平台內快速輕鬆地清理數據。
- 賦能您的專家: 模型讓領域專家可以控制定義和完善業務問題,讓他們無需通過數據團隊即可進行變更。這種彈性確保不同的團隊可以擁有自己的模型。
Metabase 中模型的缺點
- 規模/複雜性有限: 可能不適用於複雜的資料清理情境或大規模的數據處理。
範例
讓我們考慮一個線上商店的銷售交易範例資料集。原始數據可能如下所示
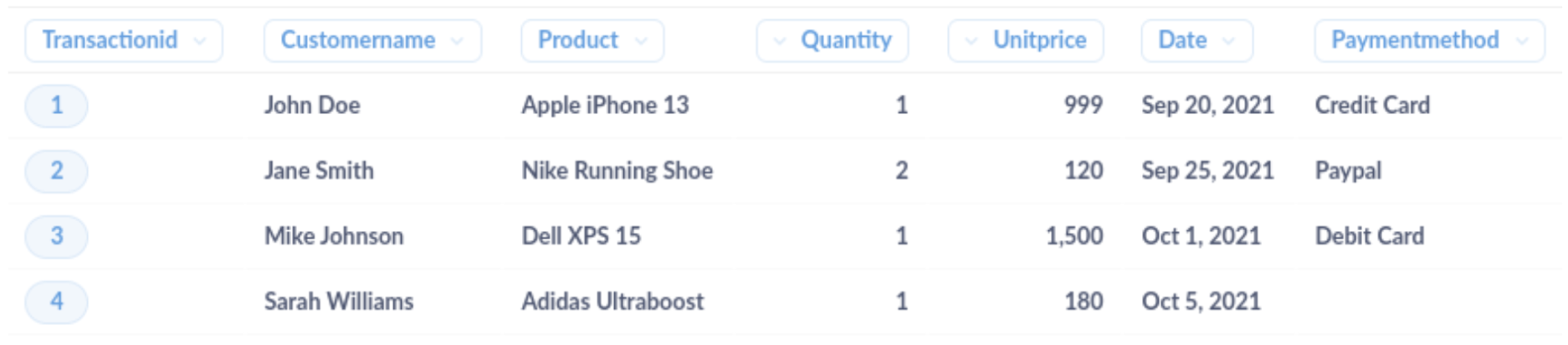
在此資料集中,有幾個問題需要解決。為了解決這些問題,您可以在 Metabase 中實作模式或函數
-
產品名稱不一致: 使用 regexextract,透過移除品牌名稱並僅保留產品型號來標準化產品名稱。範例模式:
REGEXEXTRACT([Product], '^(?:Apple|Nike|Dell|Adidas) (.*)$') -
付款方式資訊遺失: 實作一個函數,檢查是否有付款方式值遺失,並將其替換為預設值或預留位置。範例 函數:
COALESCE([PaymentMethod], '未提供')
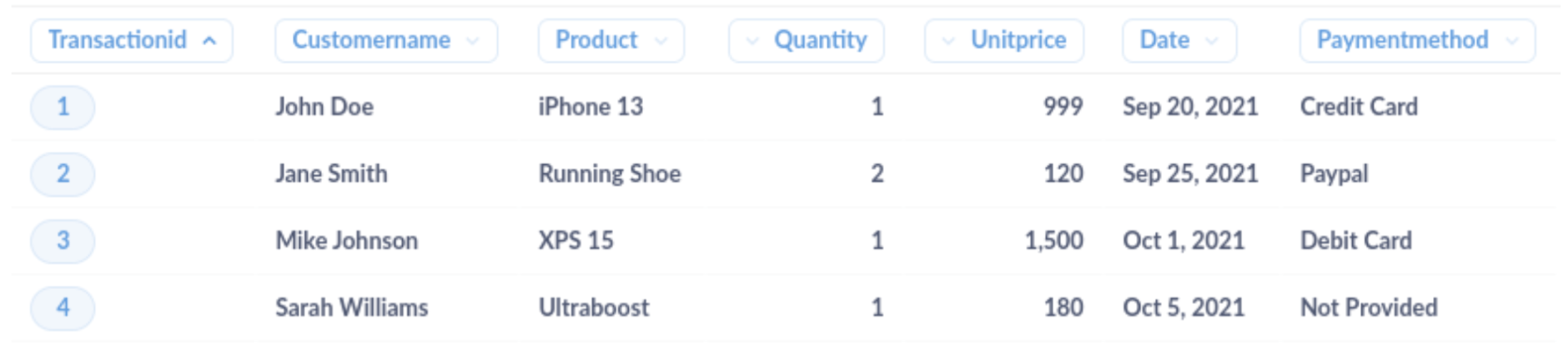
清理後的資料集應如下所示
在您的轉換管線中清理數據
您可以建立一個 SQL 查詢用於您的資料轉換管線,以確保已清理的數據被儲存並隨時可用於分析。這有助於減少在後續階段進行額外數據操作的需求。
資料轉換管線為資料清理提供了一個強大且可擴展的解決方案,尤其是在處理大型、複雜的數據集或多個來源時。但是,您必須考慮有效實作和維護此方法所需的技術專業知識。
在資料轉換管線中實作資料清理,通常需要資料工程師和分析師之間的協作。分析師可以與業務利害關係人合作,收集需求並定義規則。資料工程師可以設計和設定管線,並編寫清理和結構化數據所需的轉換。這些規則可以包括篩選掉不相關的數據、標準化格式、處理遺失值以及合併來自多個來源的數據。
轉換管線的優點
- 更智慧: 可以處理複雜的資料清理情境,並隨著數據增長而有效地擴展。
- 節省時間: 透過自動化資料清理流程,您可以減少錯誤並節省原本會花在手動資料清理上的時間。
- 解決根本原因: 實際上修復了來源數據的根本問題,而不是應用治標不治本的方法。
轉換管線的缺點
- 成本增加 + 複雜性: 需要技術專業知識,並且可能比使用模式或函數更耗費資源。可能會導致成本和複雜性增加,尤其是在資源有限的小型組織中。
- 更多額外負荷: 可能很耗時,並且可能需要隨著業務需求變化進行持續維護。
轉換管線範例
以下是客戶訂單的範例資料集。
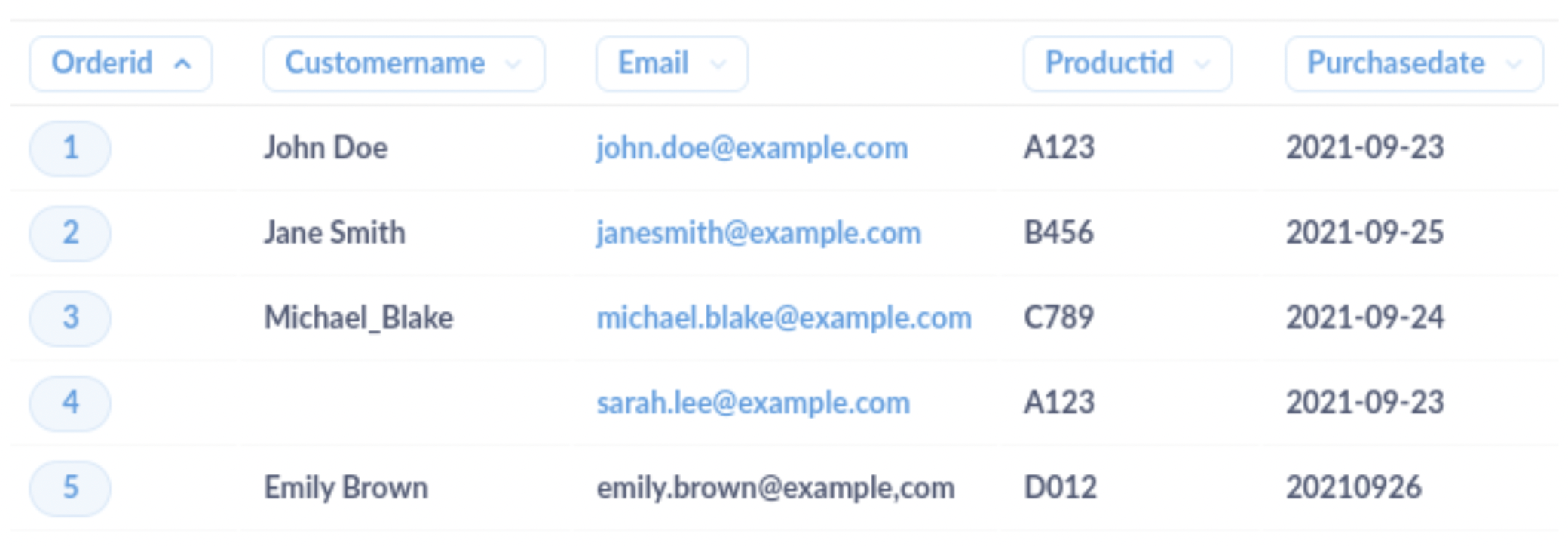
在此範例中,有幾個問題需要清理
-
CustomerName欄位中的格式不一致(例如,底線而不是空格) -
CustomerName欄位中遺失數據(NULL 值) -
第 5 列的
Email欄位中分隔符號不正確(逗號而不是句點) -
第 5 列的
PurchaseDate欄位中日期格式不一致
您可以使用 SQL 來清理數據。以下是如何執行此操作的範例
-- Create a temporary table with cleaned data
CREATE TEMPORARY TABLE cleaned_orders AS
SELECT
OrderID,
-- Replace underscores with spaces and handle NULL values in the CustomerName field
COALESCE(NULLIF(REPLACE(CustomerName, '_', ' '), ''), 'Unknown') AS CleanedCustomerName,
-- Replace comma with period in the Email field
REPLACE(Email, ',', '.') AS CleanedEmail,
ProductID,
-- Standardize the date format in the PurchaseDate field
STR_TO_DATE(PurchaseDate, '%Y-%m-%d') AS CleanedPurchaseDate
FROM
raw_orders;
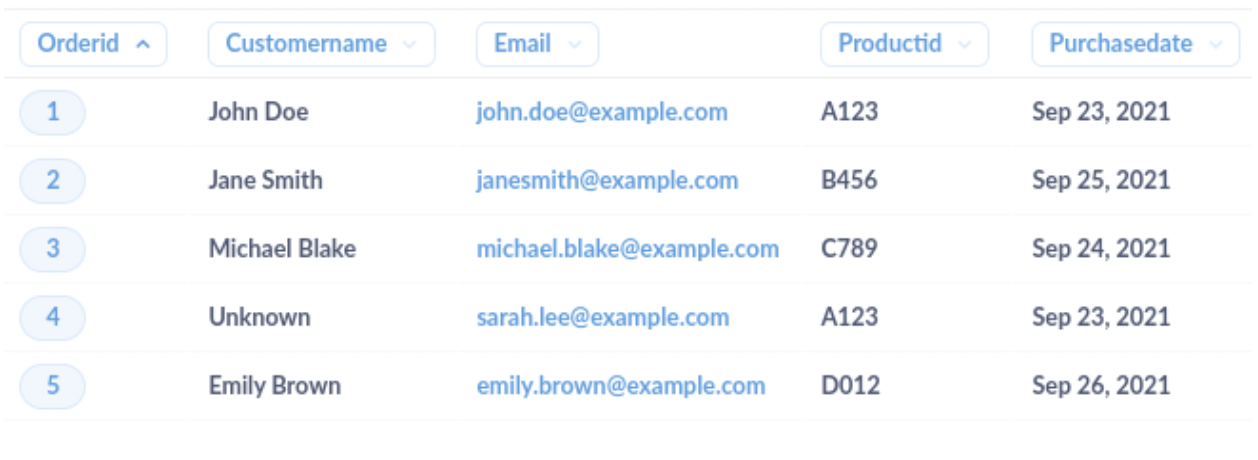
清理後的資料集將如下所示
使用 AI 清理數據
AI 正在改變我們處理資料清理的方式。先進的演算法和機器學習技術,特別是大型語言模型,例如 OpenAI 的 ChatGPT 模型,可以自動化資料清理流程。
使用 AI 的優點
-
自動化: AI 服務可以自動識別和更正數據中的錯誤、不一致和異常。這種自動化不僅節省時間,還可以降低資料清理過程中人為錯誤的風險。
-
規模: AI 服務旨在快速有效地處理大型資料集。這表示即使您的業務增長並產生更多數據,AI 驅動的資料清理解決方案也可以擴展以滿足您的需求,而不會影響準確性或速度。
-
隨著時間推移而改進: AI 服務最令人印象深刻的方面之一是它們隨著時間推移學習和改進的能力。隨著 AI 系統處理更多數據,它在識別模式和做出智慧決策方面變得更好,最終帶來更準確和高效的資料清理。
-
領域專業知識: 如果您的組織可以存取領域專家,他們的見解對於建立量身定制的資料清理規則或指導 AI 驅動解決方案的實作可能非常寶貴。
使用 AI 的缺點
-
初始投資: 實作 AI 服務進行資料清理可能需要對技術和資源進行初始投資。但是,改善資料品質和減少人工勞動的長期效益可能會超過這些成本。
-
人工監督/驗證: 雖然 AI 服務可以自動化大部分資料清理流程,但仍需要一定程度的人工監督和驗證。擁有一支了解您的數據細微差別並在需要時做出明智決策的團隊至關重要。
使用 AI 的範例
AI 可以執行的更複雜的資料清理範例是識別和解決跨多個資料來源的服裝產品屬性中的不一致性。這通常涉及理解不同屬性(例如顏色、尺寸和款式)之間的上下文、語意和關係。
範例資料集

在此範例資料集中,來自三個不同資料來源的產品屬性不一致,需要針對線上服裝店進行標準化。由於屬性的術語、順序和結構各不相同,傳統清理方法可能難以有效識別和解決這些不一致性。
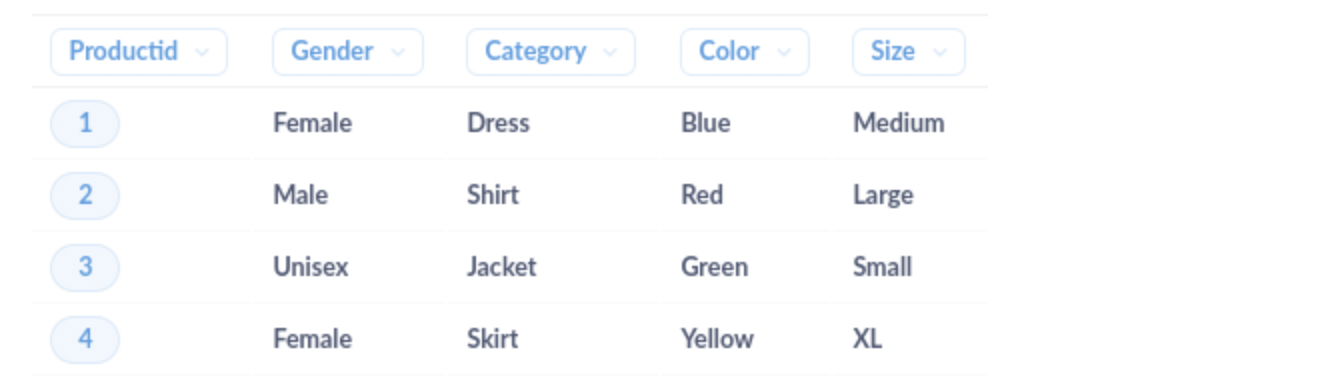
但是,AI 驅動的解決方案可以分析不同屬性之間的上下文、語意和關係,並將它們對應到標準化的屬性集。例如,AI 可以識別出「女裝洋裝,藍色,M 號」、「女性,洋裝,M 號,藍色」和「洋裝,中號,女性,顏色:藍色」都指的是相同的產品屬性,並將它們對應到單一、標準化的格式,例如「性別:女性,類別:洋裝,顏色:藍色,尺寸:中號」。
清理後的資料集將如下所示

現在我們可以將產品屬性拆分為單獨的欄位,以便更輕鬆地進行分析。
您應該採取哪種方法?
最適合您企業的資料清理方法取決於各種因素,例如數據類型和品質、資料集大小和複雜性、可用資源以及特定的業務目標。在選擇一種方法整合到您的技術堆疊之前,測試和評估不同的清理方法至關重要。通常,公司會混合使用上述方法。檢查資料來源是否與您偏好的方法相容,並確保您擁有必要的資源來有效地執行所選的解決方案。