


指標層是必要的跡象
「儀表板 A、B 和 C 上的使用者數量不同。您可以解釋一下發生了什麼事嗎?」
「此報告中此計數的定義已過時。我們可以盡快修正嗎?」
這些是我作為商業智慧分析師每週(如果不是每天)被問到的常見問題範例。這是一個指標已失控的跡象,並為必須根據資料做出決策的終端使用者造成混亂。即使我們是創建資料的人,這也為資料團隊創造了更多工作。隨著業務的成長和變化,它追蹤的指標也會隨之變化。而且隨著它收集的資料變得更加豐富,其複雜性也會隨之增加。
考慮計算使用者的基本情境。聽起來很容易做到,對吧?但以下是我在工作中必須面對的一些常見問題
- 我應該在什麼時間範圍內計算使用者?每日?每週?每月?
- 我需要依地理區域拆分嗎?該地理區域如何定義(州、縣、MSA)?
- 當計算使用者時,我如何知道是否有重複項?我在什麼細節程度下去除重複項?
- 我只想知道活躍使用者。我如何判斷使用者是否活躍?是否有旗標欄?或者如果使用者在一段時間後沒有任何交易,我是否認為使用者不活躍?那段時間是多久?
- 在計算時,我是否需要注意資料中的其他旗標或篩選器?我應該開啟還是關閉它們?取決於您的領域,還有更多無數的注意事項。
在分析中,計算事物實際上非常困難。當多個消費管道上應該相同的指標數字不正確時,使用者開始對資料失去信任,而資料團隊追蹤確切發生了什麼事會變成一件令人頭痛的事情。
什麼是指標層?
但是,這個領域中有一種不斷成長的解決方案:指標層的概念(其他術語包括無頭 BI 或指標儲存庫)。
您知道 Github 如何成為專案程式碼庫的中央儲存庫嗎?或者資料倉儲如何成為資料的單一事實來源?指標層可以成為組織中指標定義方式的中央單一事實來源。
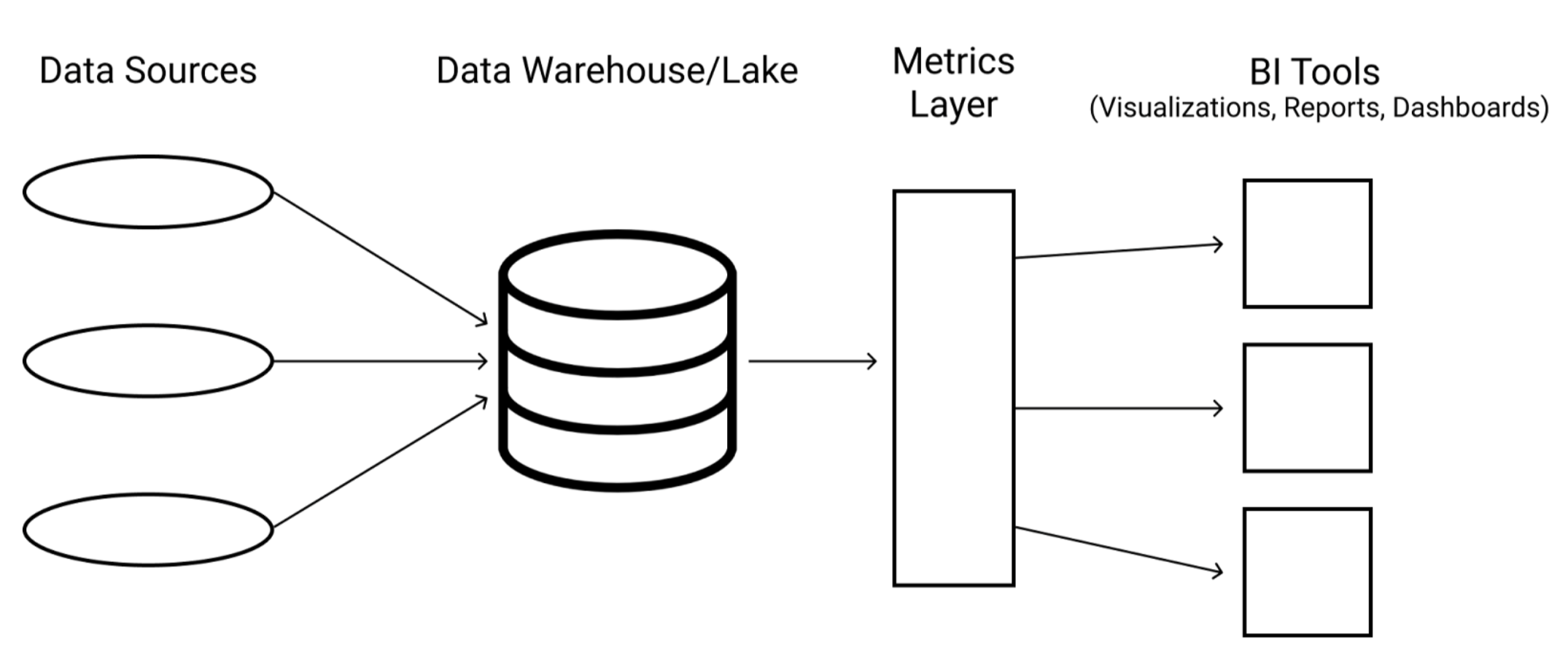 指標層應位於資料儲存位置與資料使用方式之間,以實現統一的定義
指標層應位於資料儲存位置與資料使用方式之間,以實現統一的定義
您的組織有多個儀表板。它也可能有多個商業智慧 (BI) 工具。您真的希望每次都在每個管道中定義指標的業務邏輯嗎?如果邏輯隨著業務成長而改變怎麼辦?這會增加某個實例在有人查看並做出決策時稍微偏差或過時的可能性。但是,在多個地方使用的單一、經過同意的定義可以解決這個困境,並且是 DRY 原則(Don't Repeat Yourself,不要重複自己)的一個絕佳範例。
您如何開始定義指標層?
它一開始不必是完全工程化的功能。首先,只需定義指標應如何計算即可。寫出用於建立指標的 SQL 查詢或一系列步驟,並將其儲存在多個使用者可以參考並提供意見的位置(但請注意不要將程式碼複製並貼到各種工具中)。然後將其移至多個工具可以存取定義的位置。您可以根據 SQL 查詢建立表格或檢視,並將其儲存在資料倉儲中。
當您準備好時,定義一個指標層,您可以在其中從集中位置共用指標(在撰寫本文時,Metabase 在即將推出的功能中提供了此功能)。某些工具允許各種 BI 解決方案連接到 API 以存取指標,並讓您在保持指標定義完整的情況下交換指標(因此,稱為「無頭 BI」)。
您如何定義指標層?
多種工具可以幫助您嘗試填補現代資料堆疊中這個缺失的部分。一般綱要如下
1) 判斷您想要追蹤哪些指標。聽起來很簡單,但正如我在開頭範例中概述的那樣,它可能會很快失控。您想要衡量什麼、想要如何彙總,以及想要依哪些維度對資料進行切片?您是否想要在指標中包含任何篩選器/約束?
2) 根據您選擇用於實作指標層的工具,您需要定義這些組態。在某些工具中,您將在 YAML 檔案中設定這些定義。
3) 現在您已經定義了指標,是時候測試它們了。指標層的彈性意味著,您只需定義可能性,而不是預先彙總措施和維度的每種可能組合,並讓工具處理它,以便無論誰在使用任何 BI 工具中提取指標,您最終都會得到相同的數字。上述工具提供的 API 可用於提取指標。
指標層是 BI 領域令人興奮的發展,可以為您的分析師解決許多令人頭痛的問題和重複的問題。與其鎖定定義並在所有資料使用工具中重複複雜的業務邏輯,不如嘗試在您的組織中定義指標的「單一事實來源」!