


當我顫抖的手指移到按鈕上方時,一滴汗珠從我的額頭滑落。
我不是即將發射核彈的陸軍將軍,也不是 Space X 即將發射火箭進入太空的指揮官。
我只是一位商業智慧分析師,即將**將資料模型變更合併到生產環境中**。然而,我想像我們的壓力水平是差不多的。
我當然是誇大了。
但是,任何從事資料專業工作夠久的人都知道,對現有模型進行變更會有多大的壓力。尤其是,如果您曾經發布過導致不準確、錯誤資料或錯誤結論的變更。
在進行資料模型變更時,避免失去對資料的信任
作為資料分析師,沒有什麼比利害關係人注意到生產環境中的資料不準確性更糟糕的了。
看到他們對您的資料失去信任,這是我不希望發生在我最糟糕的敵人身上的事情。這就是為什麼您可能總是會仔細檢查資料,甚至希望運行自動化測試以確保沒有重大錯誤潛入。
確保您的資料模型變更正確無誤
但是,您通常可能仍然會感到揮之不去的焦慮和擔憂,擔心自己遺漏了某些東西。
幸運的是,簡單的解決方案是比較資料模型變更中的舊版本和新版本
這是我們為確保 Infused Insight(一家協助使用 Infusionsoft 的企業透過資料洞察力來獲得更多潛在客戶和銷售額的公司)始終如一的高品質和準確資料而採用的眾多政策之一。而且這個解決方案非常有幫助。
我們在第一次應用此政策時就注意到資料中出現了意外的變更。而且自那時以來,它一次又一次地被證明非常有用。
理論上,解決方案很簡單
在變更模型的查詢後,分析師應寫下他們預期結果資料如何變更的假設,例如
「先前為 NULL 的廣告行動呼籲網址,現在應包含有效的網址。」
接下來,他們應該對舊查詢和新查詢的結果運行比較,以比較所有欄位值,並偵測所有新增和刪除的列。
然後,他們檢查是否只有預期的變更應用於資料。這似乎是一項非常常見的任務,並且應該有很多工具(最好是開放原始碼)可以實現它。
選擇正確的工具來支援您的資料模型變更
現實情況看起來有所不同。
有一些工具可以完全滿足我的需求,並提供使用者友善的 UI,但它們是封閉原始碼、相當昂貴,而且最重要的是,僅在 Windows 上可用。
我們的最終解決方案是建立一個 Jupyter 筆記本,使用 python、pandas 和 datacompy 來比較表格的舊版本和新版本。您可以將它與 pandas 支援的任何資料庫,甚至 CSV 檔案一起使用。
結果是一個 .txt 檔案,其中包含變更摘要,以及一個 SQLite 資料庫,可讓您詳細查詢所有變更的欄位和列。
而 SQLite 資料看起來像這樣
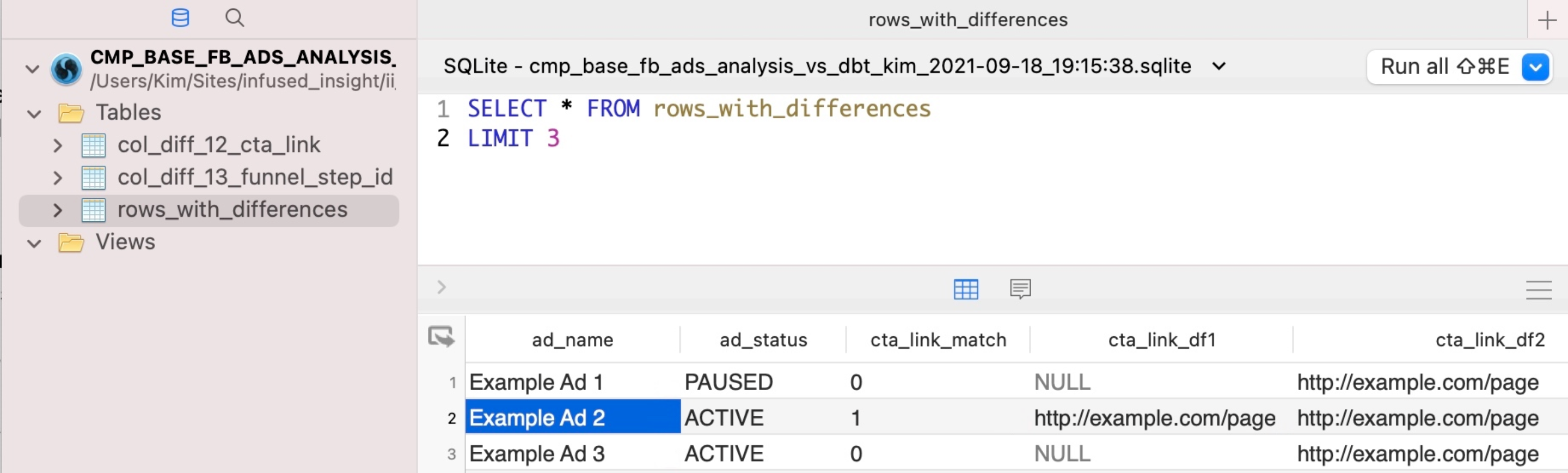
在螢幕截圖中,您可以看到 rows_with_differences 表格上的查詢。此表格包含在兩個版本之間發現差異的所有列。
對於有變更的欄位(例如 cta_link 欄位),您會獲得三個欄位(_match、_df1 和 _df2),可讓您查看變更的內容並輕鬆篩選資料。但是,在所有列中都沒有變更的欄位(例如 ad_name 和 ad_status)沒有這些額外欄位。
這樣,您可以一目了然地看到發生了什麼變更,也可以將變更的資料與列的其餘資料放在一起查看。
我已將程式碼發布為 github 上的 Jupyter 筆記本,您可以按照以下步驟進行學習。
如何為您的資料模型變更執行相同類型的比較
首先,您需要下載程式碼並安裝 python 依賴項。
git clone git@github.com:Infused-Insight/sql_data_compare.git
cd sql_data_compare
pip install -r requirements.txt
接下來,您將需要打開 data_compare.ipynb 檔案。您可以選擇使用 jupyter 伺服器打開它…
jupyter notebook data_compare.ipynb
或者您可以下載 VSCode 並在那裡運行它。那是我偏好的方法。打開 jupyter 筆記本後,您需要調整設定。
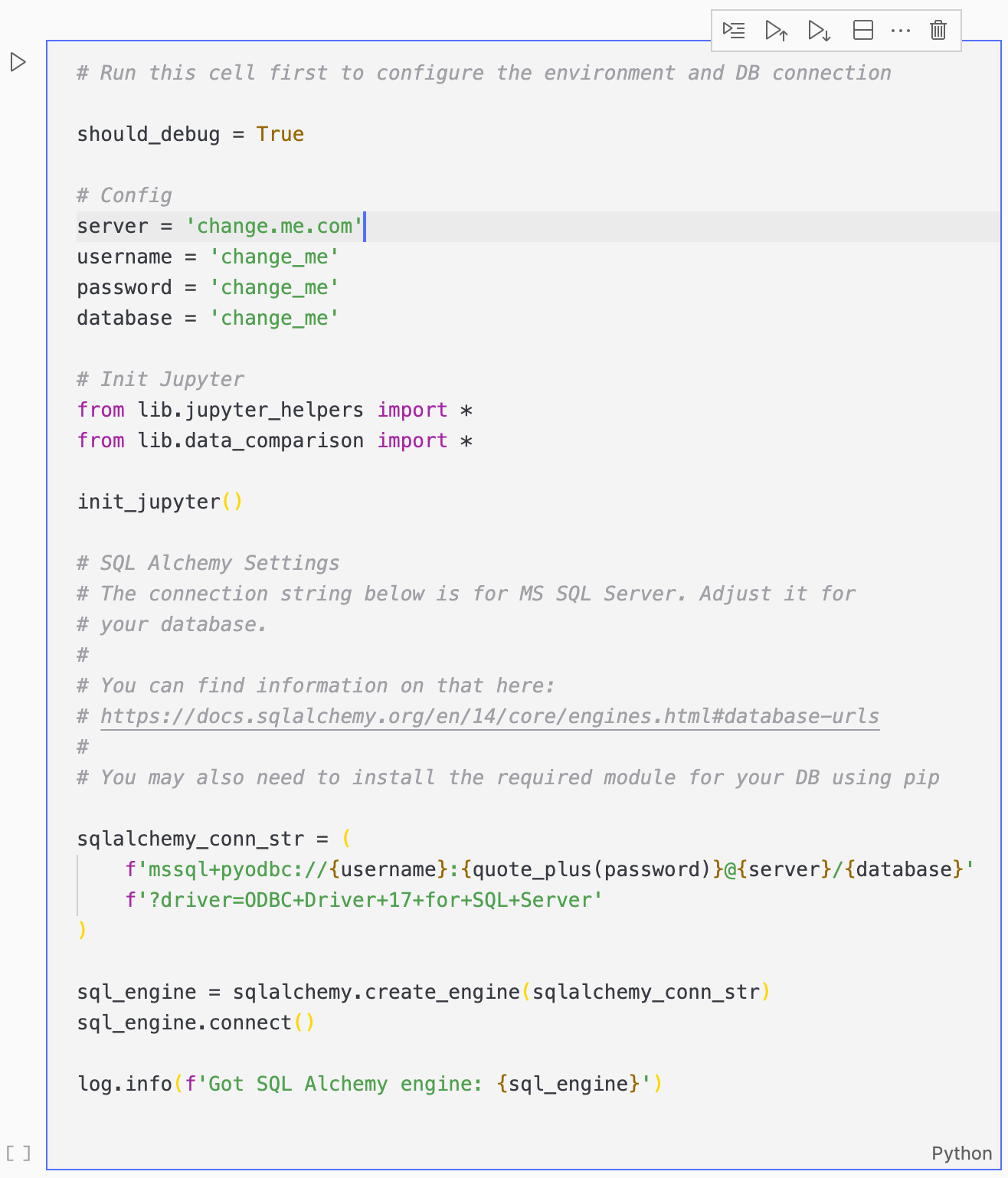
該解決方案使用 python 的 SQLAlchemy 模組從 SQL 資料庫載入資料,然後使用 pandas 和 datacompy 進行比較,最後將結果寫入 SQLite 資料庫。
因此,第一步是配置 SQL 資料庫設定和 SQLAlchemy 連接字串。
在上面的範例中,它被配置為連線到 MS SQL 伺服器,但您可以將其變更為 SQLAlchemy 支援的任何資料庫。
您可以參考 他們的資料庫 URL 文件 以取得更多詳細資訊。
之後,您可以在第二個 jupyter 儲存格中開始比較。

只需調整設定並運行它即可。
您將在 ./comparison/ 目錄中找到結果報告和包含變更的 SQLite 資料庫。
結論:資料模型變更
我希望這個簡單的解決方案能幫助您避免錯誤,並讓您有信心改進現有模型,而不會擔心破壞某些東西。