


身為資料工程師,我一直想開發資料驅動的應用程式,以推動資料科學和商業智慧。我想建立能增加價值並提供競爭優勢的產品和服務,因為資料正逐漸成為智慧決策的來源。
我了解到準確且即時的資料是關鍵驅動因素。
我也看過一些組織缺乏資料,並且不真正了解績效、產業等。他們傾向於根據不準確的資訊或他們認為正確的資訊來做決策。
同時,善用資料的公司正在更深入了解其市場、業務和競爭對手地位。這類資訊能建立信心。這是一種競爭優勢。
資料管線如何運作?
那麼,組織如何才能保持其資料為最新狀態,並朝著這種優勢努力呢?
資料管線…分析成功的基石。
一般來說,資料驅動型公司會聘請資料工程師/架構師,在其基礎架構中實作資料管線的擷取-轉換-載入 (ETL) 工具。
但他們究竟是如何做到的呢?
建立資料管線有哪些步驟?
資料管線將包含幾個步驟,包括從來源擷取、資料前處理、驗證和資料目的地。讓我們來看一個簡單的範例。
在這個使用案例中,我從黑膠唱片市場抓取資料,並且想要對這些商品的定價進行分析。
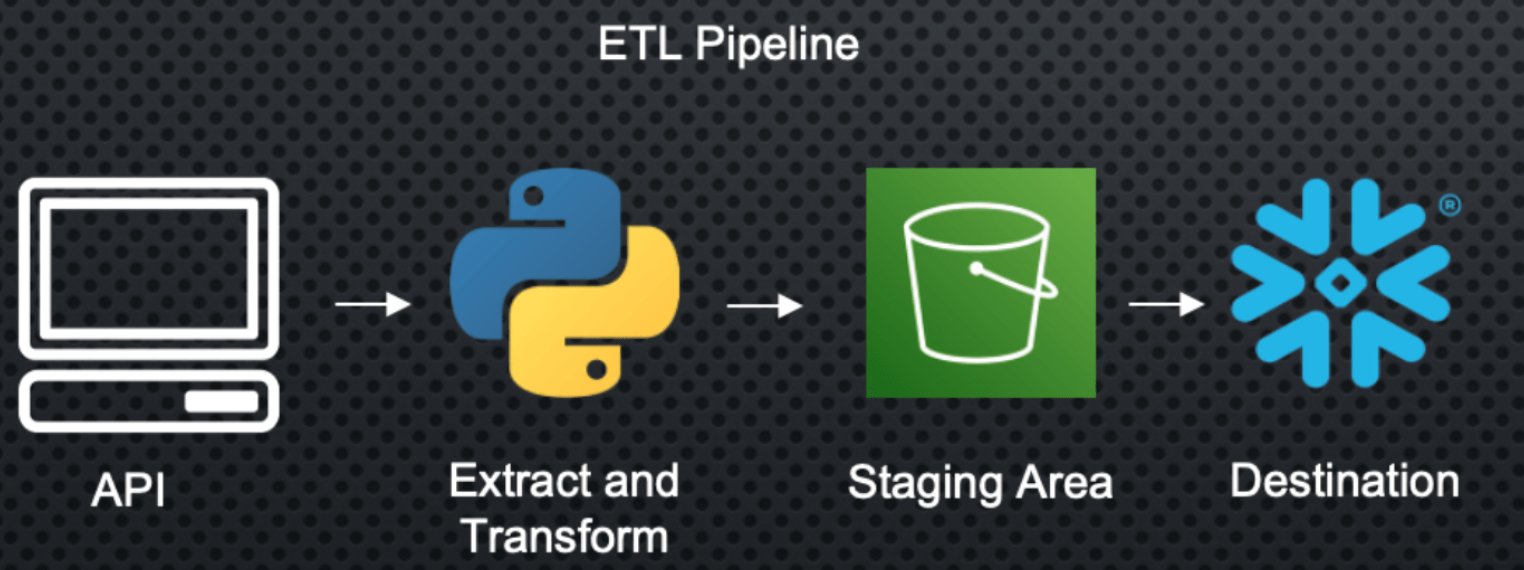
建立資料管線的流程
這裡的第一步是點擊 API 或資料庫,並使用我製作的 Python 腳本擷取我們正在尋找的資料。
這太棒了,因為我現在有資料了!
問題是資料格式不一定是我想要的格式,所以我需要執行一些轉換才能取得所需的資料集。
完成之後,我可以將其載入到暫存區,例如 AWS S3 或 Azure Blob 以進行資料儲存。我將其稱為暫存區,因為我希望將其用作最終目的地的墊腳石。
為了確保其可靠性,我需要建立一些測試、警示和備份計畫,以防發生錯誤或耗時過長。最後,我的資料倉儲將識別暫存區中的新記錄,並擷取新資料,以便為組織內的分析師和資料科學家維護最新的資料集。
成功了!現在,我的報告和機器學習模型已連線到這個最終資料來源,該來源會以我選擇的速率饋送資料!管線已就位、已部署,而且我不再需要手動觸碰或擷取資料 (希望如此)。
這只是一個資料來源,但現在我可以找到其他來源,看看是否可以透過其他管線引入外部來源,以強化我的資料,並持續建立資料管線的競爭優勢。查看以下程式碼,以更深入了解 ETL 程式碼。
import psycopg2
import csv
import boto3
import configparser
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
from time import time
from datetime import datetime
# config credentials from env
access_key_id = os.environ.get('AWS_ACCESS_KEY_ID')
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
bucket_name = 'discog-data'
# scrape data
startTime = time()
url = '...'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.find(id="pjax_container")
record_elements = results.find_all("tr", class_="shortcut_navigable")
item_list = []
price_list = []
sellers_list = []
total_price_list = []
link_list = []
for record_element in record_elements:
item_description = (record_element.find("a", class_="item_description_title"))
item_list.append(item_description.text)
price = (record_element.find("span", class_="price"))
price_list.append(price.text)
seller = record_element.find(lambda tag: tag.name == 'a' and tag.get('href') and tag.text and '/seller/' in tag.get('href'))
sellers_list.append(seller)
total_price = (record_element.find("span", class_="converted_price"))
total_price_list.append(total_price)
record_info = record_element.find(lambda tag: tag.name == 'a' and tag.get('href') and '/sell/' in tag.get('href'))
link = record_element.find("a", class_="item_description_title", href=True)
link_list.append(link['href'])
# create cols from item description
artists = [str(item).split('-')[0].rstrip() for item in item_list]
albums = [str(item).split('-')[1].lstrip() for item in item_list]
album_class = [str(item[item.find("(")+1:item.find(")")]) for item in item_list]
total_price_list = [item.text if item is not None else '0' for item in total_price_list]
my_dict = {'item_description': item_list,
'artists': artists,
'album': albums,
'album_class': album_class,
'seller': sellers_list,
'price': price_list,
'total price': total_price_list}
filename = f'discogs_market_data_{datetime.now().strftime("%Y%m%d-%H%M")}.csv'
df = pd.DataFrame(my_dict)
df.to_csv(filename, index=False)
# load file to S3
s3 = boto3.client('s3',
aws_access_key_id=access_key_id,
aws_secret_access_key=aws_secret_access_key)
s3_file = filename
s3.upload_file(filename, bucket_name, s3_file)
print(f' execution time: {(time() - startTime)}')