結構化
什麼是綱要?
**綱要**是一種設計或結構,用於定義資料集的組織:哪些欄被分組到表格中、這些表格彼此之間有何關聯,以及定義這些欄的規則和資料類型。
綱要是一個過於常用的術語;它是一個抽象的詞,累積了許多不同的定義,因此可能會讓人感到困惑。根據上下文,綱要可能意味著
最後,綱要偶爾也意味著特定於您正在使用的資料庫平台的事物,例如在 Oracle 中,綱要指的是同一個使用者在資料庫中建立的所有物件。
綱要作為整體結構:設計與實作
一旦您從高階角度了解資料如何組合在一起(即您的概念性資料模型),下一步就是建立一個反映該資料模型的綱要,將其從抽象概念轉變為您的組織可以使用並填入資訊的資料庫。
廣義來說,這個過程由兩個主要步驟組成
- 設計:規劃資料庫的結構,在此過程中建立實體關係圖 (ERD)。
- 實作:使用該 ERD 來產生 SQL 命令,這些命令在您的資料庫中執行時,將建立您想要的綱要。
您的綱要設計流程看起來如何,取決於您處理的是交易型還是分析型資料庫,以及您是從頭開始還是已經開始收集資料。無論您在何時設計綱要,您都必須深入思考組織的需求,以及您預期會向資料提出的問題。
寫入時綱要與讀取時綱要
大多數傳統的關聯式資料庫都使用**寫入時綱要**系統,其中資料在寫入到該資料庫之前,會先經過驗證並格式化為綱要。由於要寫入的資料必須符合您建立的任何特定資料完整性規則(例如要求欄位中的所有值都是唯一的、不接受欄位中的空值,或以特定方式格式化日期),因此將這些新資料新增到資料庫可能會很慢。但是,讀取時間很快,因為資料已經過驗證。
在**讀取時綱要**系統中,資料(例如在資料湖中)僅在讀取或從該資料庫中提取後才進行驗證。讀取時綱要系統往往更具彈性,因為您可以儲存非結構化資料,而無需擔心它是否符合嚴格的資料模型。在這種情況下,寫入資料的速度更快(因為資料在載入時不需要驗證),但查詢需要更多時間才能執行。
您選擇寫入時綱要還是讀取時綱要策略,將取決於您組織的需求和特定用例。如果擁有結構嚴謹且一致的資料集對您的組織很重要,則寫入時綱要系統可能是您的最佳選擇。相反地,如果您經常需要提取各種資料,但並非總是確切知道資料的外觀,則您可能需要使用讀取時綱要系統。
邏輯綱要和實體綱要
無論您使用的是寫入時綱要還是讀取時綱要系統,您都需要考慮資料庫結構及其實作 — 即您的邏輯綱要和實體綱要。邏輯綱要定義資料的結構,而該結構的實際實作(例如您如何以及在哪裡儲存組成資料庫的檔案和程式碼)屬於實體綱要。
邏輯綱要
**邏輯綱要**是透過繪製表格及其欄位如何相互關聯來建立的。在建立邏輯綱要時,您將建立表格、關係、欄位和檢視,並回答以下問題
- 我們正在收集或想要收集哪些資料?
- 您的資料庫(或其中的個別綱要)需要哪些表格?
- 這些表格之間有何關聯?
- 每個表格需要哪些欄位?
- 這些欄位的資料類型是什麼?
- 哪些欄位是必填的?
綱要作為圖表:繪製實體和關係
在回答這些和其他問題時,您可能會草擬一個實體關係圖 (ERD),其中定義了每個表格、其欄位、其完整性約束,以及這些表格之間的關係,包括建立這些連線的主鍵和外鍵,以及表格之間的關係是一對一、一對多還是多對一。視覺化表格及其相互關聯的方式,也可以揭示任何重大遺漏或衝突。是的,有時您會看到這些圖表本身被稱為綱要。
下圖顯示了一個綱要的實體關係圖,其中包含兩個表格,PRODUCTS 和 MANUFACTURER。「(PK)」和「(FK)」註釋告訴我們哪些欄位是主鍵和外鍵,而連結這些表格的線條表示一對多關係,即一個製造商可以連結到多個產品。
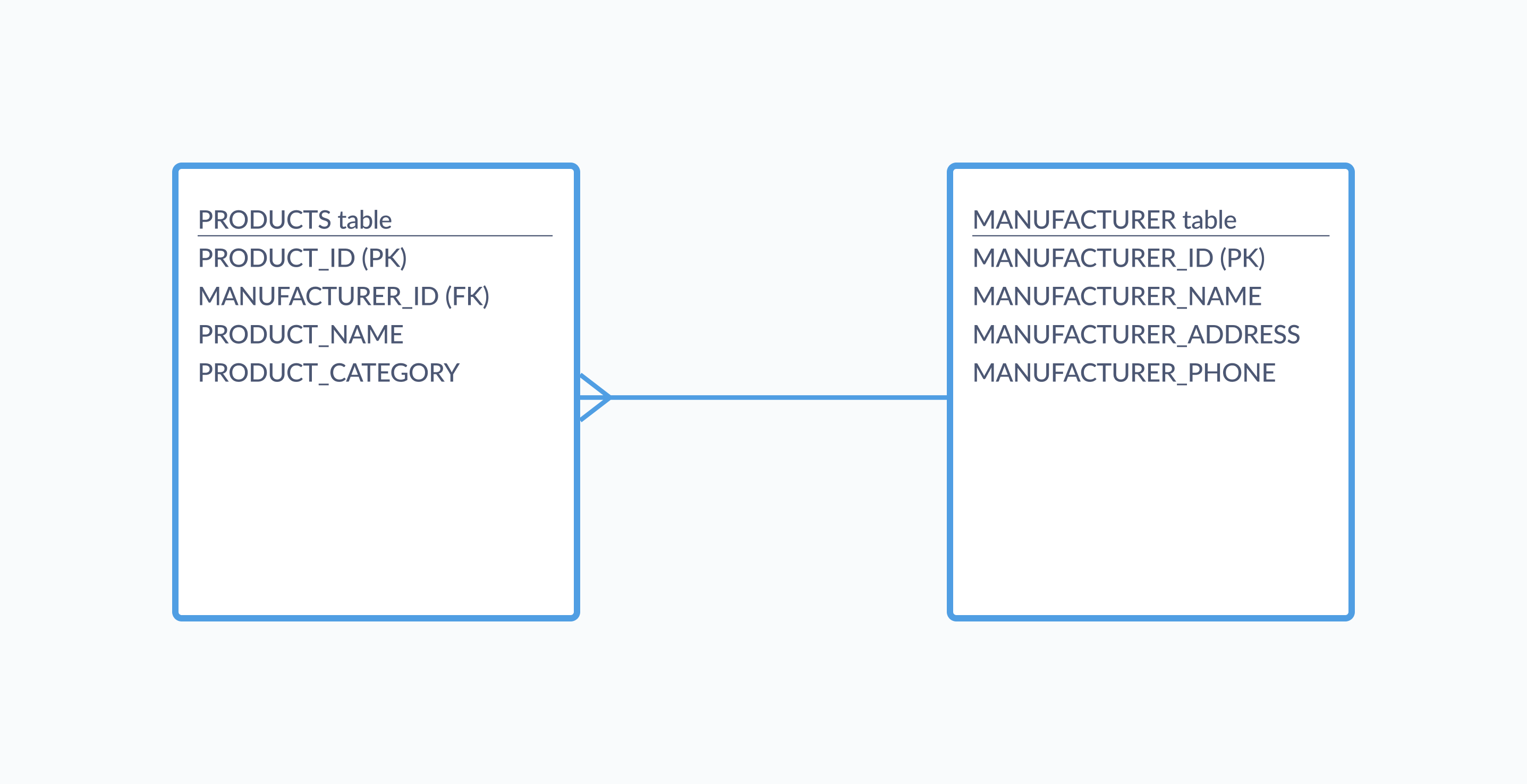
您可以在紙上或使用設計軟體繪製綱要,這些軟體可以直接將您的圖表轉換為實作資料庫所需的 SQL 命令。此時,您的綱要是平台無關的;繪製這些規則和關係不會將您束縛於任何單一資料庫軟體。
實體綱要
一旦您確定了資料庫的邏輯配置,您將建立一個**實體綱要**,以將其實作到特定的 RDBMS 中,定義資料庫檔案將位於何處,以及它們在磁碟上的儲存分配。
綱要作為眾多表格中的一個集合
如果您的資料庫只有少數使用者,並且包含每個人都需要存取的資料,則單個表格集合可能就足夠了,但您可能會發現,依賴資料庫中的單個綱要對您的組織來說是不夠的。如果您要處理跨許多表格的資料(想想數十個、數百個或數千個),將這些表格分組到不同的綱要中將有助於組織,使您可以將相似的資訊儲存在一起,同時保留在必要時跨綱要查詢的能力。
在資料庫中保留多個綱要,從安全角度來看也可能很有幫助,例如將包含敏感資訊的表格分隔到只有需要的人才能存取的綱要中,通常與檢視結合使用。
交易型與分析型資料庫的綱要設計
在考慮交易型資料庫(也稱為營運資料庫)的綱要時,您的資料將需要進行一定程度的正規化,並遵守資料完整性標準,因為對於那些小型交易和 OLTP 而言,效率和效能至關重要。
為分析型資料庫設計綱要看起來會有所不同。首先,您可能已經收集了原始資料,可能來自多個來源,現在需要強加一些結構才能對其進行分析。在這種情況下,冗餘是可以接受的,因為分析型資料庫更重視可探索性,而較少重視效能。在這裡,您的綱要也可以定義得更鬆散,因為不需要固定的模式(例如正規化)。分析型資料庫的綱要設計更多的是關於了解來自不同來源的資料位於何處,以及了解您需要聯結哪些表格才能回答您有的問題。
星狀綱要
您將在分析型資料庫中看到的一種常見結構是**星狀綱要**,它將資料分為事實表格(即量化資料),這些表格與描述這些事實的多個維度表格相關聯。在星狀綱要的簡單實作中,多個維度表格都環繞著單個事實表格並與之相關,在圖表形式中看起來像一顆星星,事實表格位於中心,如下所示
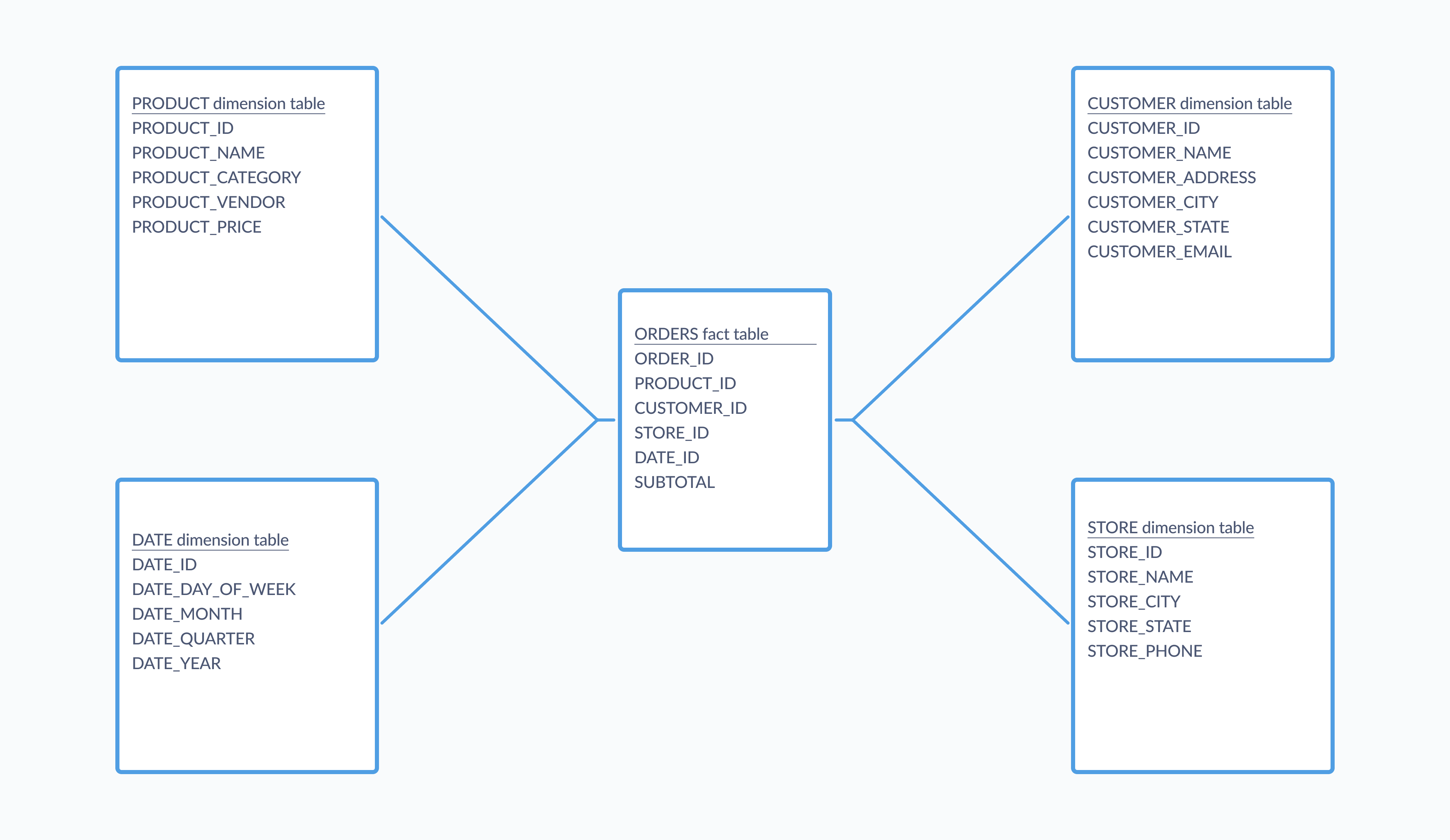
星狀綱要中的表格通常是非正規化的,這可以提高分析查詢的效能。
建立資料庫綱要
大多數資料庫平台(例如 Redshift 和 PostgreSQL)都使用「綱要」來表示資料集的配置,以及該資料集內表格和其他命名物件的非巢狀分組,儘管 Oracle 將綱要定義為單個資料庫使用者建立和擁有的所有物件。
若要在 RDBMS 中建立綱要,請使用查詢 CREATE SCHEMA,例如在此範例中,我們建立一個綱要,其中包含兩個由 customer_id 欄位連結的表格
CREATE SCHEMA new_schema;
CREATE TABLE new_schema.orders (
order_id
product_id
customer_id
subtotal
order_date
)
CREATE TABLE new_schema.customers (
customer_id
customer_name
customer_address
customer_email
);
這是一個非常簡單的綱要;我們沒有指定資料類型或表格中欄位的任何其他約束。如果我們想要在 customers 表格中要求 customer_id 欄位,並指示其資料類型為整數,我們會像這樣格式化該欄位
customer_id INT NOT NULL
請注意,在 MySQL 中,CREATE SCHEMA 與 CREATE DATABASE 同義。